源码解析libpmemobj分配释放内存
libpmemobj中的内存池布局大致如下所示:
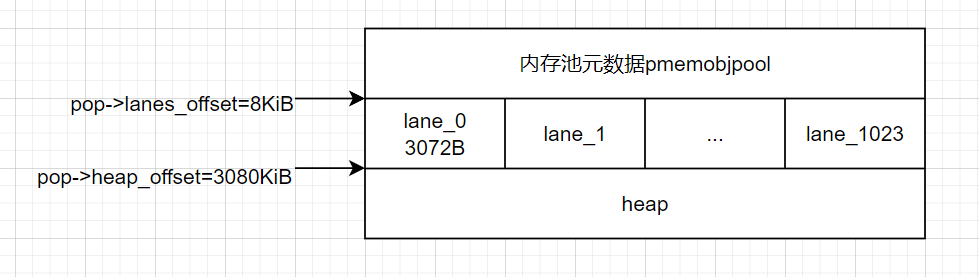
内存池大致分为了3个主体:内存池元数据、用于保存事务操作的通道lane、用于对象内存分配的堆heap。
在libpmemobj构建的内存池时,有一个参数是内存池的大小,大小不一样,堆的内部结构也会有些不一样,最主要表现在堆中的区域zone数量不一,小的内存池可能只有一个区域,大的内存池可以有很多个。
由于大多数操作系统使用ASLR特性,一旦内存映射至应用程序地址空间之后,池的基地址会在执行和系统重启之间改变。为了表示数据在内存池中的位置,PMDK将数据放在”对象”中,对象会有一个相对于池基地址的偏移量,在PMDK中的表现形式就是PMEMoid这个结构体:
/*
* Object handle
*/
typedef struct pmemoid {
uint64_t pool_uuid_lo; // 标识内存池文件
uint64_t off; // 对象在文件中的偏移量
} PMEMoid;
通过内存池中的内存申请对象的时候,对象的大小不一样,分配的策略也不一样。文档并不会覆盖到调用过程中的所有代码,重点关注堆的布局以及内存分配的策略。
初始化堆
现在有这样一个程序:
#include <stdio.h>
#include <string.h>
#include <libpmemobj.h>
#define LAYOUT_NAME "intro_1"
#define MAX_BUF_LEN 32
struct my_root
{
size_t len;
char buf[MAX_BUF_LEN];
};
int main(int argc, char *argv[])
{
PMEMobjpool *pop = pmemobj_create(argv[1], LAYOUT_NAME,
PMEMOBJ_MIN_POOL, 0666);
PMEMoid root = pmemobj_root(pop, sizeof(struct my_root));
struct my_root *rootp = pmemobj_direct(root);
char buf[MAX_BUF_LEN] = "Hello, World!";
rootp->len = strlen(buf);
pmemobj_persist(pop, &rootp->len, sizeof(rootp->len));
pmemobj_memcpy_persist(pop, rootp->buf, buf, rootp->len);
pmemobj_close(pop);
return 0;
}
在程序调用 pmemobj_create 这个函数时,内存池会被初始化,其中就包括初始化内存池中的堆,下面是相关的代码:
/*
* heap_init -- initializes the heap
*
* If successful function returns zero. Otherwise an error number is returned.
*/
int
heap_init(void *heap_start, uint64_t heap_size, uint64_t *sizep,
struct pmem_ops *p_ops)
{
struct heap_layout *layout = heap_start;
// 初始化heap_hdr
layout->header = {
.signature = HEAP_SIGNATURE,
.major = HEAP_MAJOR,
.minor = HEAP_MINOR,
.unused = 0,
.chunksize = CHUNKSIZE,
.chunks_per_zone = MAX_CHUNK,
.reserved = {0},
.checksum = 0
};
pmemops_persist(p_ops, &layout->header, sizeof(struct heap_header));
// 计算堆中区域的数量
unsigned zones = heap_max_zone(heap_size);
for (unsigned i = 0; i < zones; ++i) {
struct zone *zone = ZID_TO_ZONE(layout, i);
// 置零zone_hdr
pmemops_memset(p_ops, &zone->header, 0,
sizeof(struct zone_header), 0);
// 置零区域中的第一个chunk_hdr
pmemops_memset(p_ops, &zone->chunk_headers, 0,
sizeof(struct chunk_header), 0);
}
*sizep = heap_size;
pmemops_persist(p_ops, sizep, sizeof(*sizep));
return 0;
}
区域的大小有一个规定的区间 [768Kib, 16Gib] ,堆中区域的数量就是对堆大小除以16Gib向上取整。
#define ZONE_MAX_SIZE (sizeof(struct zone) + sizeof(struct chunk) * MAX_CHUNK)
Expands to:
(sizeof(struct zone) + sizeof(struct chunk) * ((65535) - 7))
例如大小为33Gib,那么堆中就有(33/16+1) = 3个区域:
| zone1 | zone2 | zone3 |
| 16GiB | 16GiB | 1GiB |
另外,假如除开MAX_ZONE,堆中剩余的空间不足768Kib,那么剩余的空间不会被当作一个区域:
| zone1 | zone2 | hole |
| 16GiB | 16GiB | 767KiB |
在这个程序中,因为选的是最小的内存池,其中就只有一个zone,在这个函数完成之后,堆的初始化也就完成了,刚开始是这个样子的,这里在chunk_hdr数组到下一个区域的首地址之间的空间就都是给用户申请内存用的payload,在后面会进一步初始化:
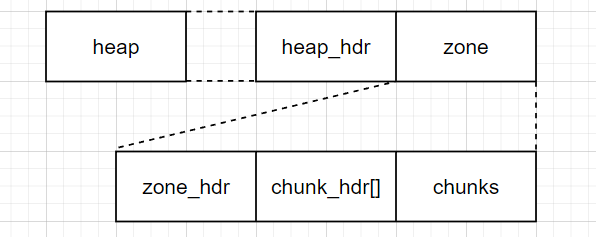
内存分配器
前面说到在堆中分配内存给用户的形式是对象,在看分配对象的过程之前,首先来看一下内存分配器中有哪些比较重要的组件。
分配类alloc_class
在堆中分配内存,首先第一步需要确定的就是分配内存所需要用到的分配类。分配类有很多,它们都被组织到了DRAM中的一个数组alcasses中,由于是在DRAM中存储的,在程序重启之后,分配类需要重新创建,创建完之后的数组是这个样子(aclass0没有初始化rdsc字段):
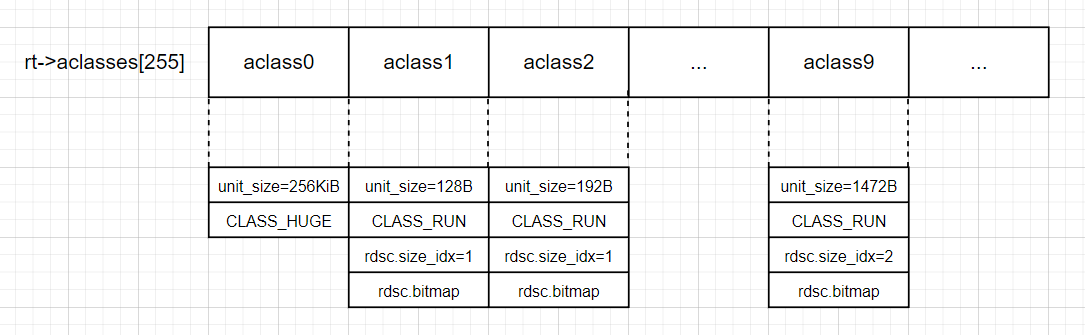
可以看到aclass中的unit_size都是64的倍数,这样主要是为了保证cacheline对齐。下面是分配类的结构体,注释中的内容可以在看完内存分配器中的其他组件之后再回头来看:
struct alloc_class {
uint8_t id;
uint16_t flags;
// 用当前分配类进行对象分配时run中的block_size
size_t unit_size;
enum header_type header_type;
// 当前分配类分配的块是属于MEMORY_BLOCK_RUN/MEMORY_BLOCK_HUGE
enum alloc_class_type type;
/* run-specific data */
struct run_descriptor rdsc;
};
/* runtime information necessary to create a run */
struct run_descriptor {
uint16_t flags;
size_t unit_size; // 用当前分配类进行对象分配时run中的block_size
uint32_t size_idx; // 当前分配类下的run所需要的CHUNK数量
size_t alignment;
unsigned nallocs; // run中blocks的数量
struct run_bitmap bitmap;
};
/* runtime bitmap information for a run */
struct run_bitmap {
unsigned nvalues; // values数组的长度,只是用来保证数据能与cacheline对齐
unsigned nbits; // run中blocks的数量
size_t size; // 位图的大小
uint64_t *values; // 指向run中存放data的部分
};
内存块memory_block
前面提到分配类的时候可以看到分配类有两种类型:CLASS_HUGE 和 CLASS_RUN,这两种类型和memory_block的两种类型MEMORY_BLOCK_HUGE、MEMORY_BLOCK_RUN相互对应。
内存块memory_block相当于一个指针,这个指针保存的并不是内存块的地址,而是内存块在堆中的偏移,这样做的好处是可以在进程重启后依然能通过偏移量找到对应的块。来看一下这个结构体的成员变量:
struct memory_block {
uint32_t chunk_id; /* index of the memory block in its zone */
uint32_t zone_id; /* index of this block zone in the heap */
/*
* Size index of the memory block represented in either multiple of
* CHUNKSIZE in the case of a huge chunk or in multiple of a run
* block size.
*/
uint32_t size_idx;
/*
* Used only for run chunks, must be zeroed for huge.
* Number of preceding blocks in the chunk. In other words, the
* position of this memory block in run bitmap.
*/
uint32_t block_off;
const struct memory_block_ops *m_ops;
struct palloc_heap *heap;
enum header_type header_type;
enum memory_block_type type;
struct run_bitmap *cached_bitmap;
};
下面再来介绍一下两种类型的memory_block,首先是MEMORY_BLOCK_HUGE,这种内存块是直接由chunk支持的。换言之,一个huge_block是由至少一个CHUNKSIZE大小(256kb)的块组成。
它的持久表示可以看作是一个具有可变长度元素的数组链表,这个列表就是struct zone的成员变量chunk_header数组,数组中的一个元素直接就对应了一个CHUNK。
struct zone {
struct zone_header header;
struct chunk_header chunk_headers[MAX_CHUNK];
struct chunk chunks[];
};
struct chunk_header {
uint16_t type; // 对应的chunk属于哪种type
uint16_t flags;
uint32_t size_idx; // huge_block的长度
};
enum chunk_type {
CHUNK_TYPE_UNKNOWN, // 0
CHUNK_TYPE_FOOTER, // 1
CHUNK_TYPE_FREE, // 2
CHUNK_TYPE_USED, // 3
CHUNK_TYPE_RUN, // 4
CHUNK_TYPE_RUN_DATA, // 5
MAX_CHUNK_TYPE // 6
};
| U | 表示一个size_idx为1的used_chunk,它的类型信息(CHUNK_TYPE_USED)就存储在相应的chunk_header数组元素中。 | F…R | 表示一个size_idx为5的free_chunk,中间三个chunk对应的chunk_header数组元素不应使用。另外,所有大小大于1的chunk必须在最后一个相应的header数组中有一个FOOTER。 |
一个chunk_header数组元素可以在单一的故障安全原子操作中更新,因为它的大小只有64字节。
然后来介绍一下MEMORY_BLOCK_RUN,run内存块具有CHUNK_TYPE_RUN的chunk_type。在chunk_run中,整个chunk会被细分为更小的unit,这些units由一个位图来进行管理,位图中的每个位都会对应一个unit,一个unit的大小(memory_block->size_idx)就是对应分配类的unit_size。
来看一下chunk_run的数据结构:
struct chunk_run_header {
uint64_t block_size;
uint64_t alignment; /* valid only /w CHUNK_FLAG_ALIGNED */
};
struct chunk_run { /* sizeof chunk_run = 256kb */
struct chunk_run_header hdr;
uint8_t content[RUN_CONTENT_SIZE]; /* bitmap + data */
};
位图bitmap
这个应该是属于分配类的一部分,但是我觉得这个结构很重要因此单独列出一小节来讲。
当内存块memory_block的类型是MEMORY_BLOCK_RUN的时候,管理run中的blocks会用到位图,run的位图是在初始化分配类的时候,需要初始化aclass->rdsc->bitmap,这时候初始化的位图相当于是一个模板,后面run中的位图都会直接从这份模板中拷贝一份。
/*
* alloc_class_new -- creates a new allocation class
*/
struct alloc_class *
alloc_class_new(int id, struct alloc_class_collection *ac,
enum alloc_class_type type, enum header_type htype,
size_t unit_size, size_t alignment,
uint32_t size_idx)
{
struct alloc_class *c = Malloc(sizeof(*c));
// ...
switch (type) {
// ...
case CLASS_RUN:
c->rdsc.alignment = alignment;
memblock_run_bitmap(&size_idx, c->flags, unit_size,
alignment, NULL, &c->rdsc.bitmap);
c->rdsc.nallocs = c->rdsc.bitmap.nbits;
c->rdsc.size_idx = size_idx;
/* these two fields are duplicated from class */
c->rdsc.unit_size = c->unit_size;
c->rdsc.flags = c->flags;
// ...
}
c->id = (uint8_t)id;
ac->aclasses[c->id] = c;
return c;
}
/*
* memblock_run_bitmap -- calculate bitmap parameters for given arguments
*/
void
memblock_run_bitmap(uint32_t *size_idx, uint16_t flags,
uint64_t unit_size, uint64_t alignment, void *content,
struct run_bitmap *b)
{
/*
* 假如设置了FLEX标志(默认会设置),那么这个位图就具有可变大小的values数组。数组的大小取决于下面三点:
* alignment - 初始的run对齐可能需要至多一个unit
* size_idx - run越大,携带的unit就越多
* unit_size - unit_size越小,每个run的unit数量就越多
* 在分配数据的开头是cacheline对齐的,这个对齐要求意味着某些bitmap values可能保持未使用,仅用作数据填充
*/
if (flags & CHUNK_FLAG_FLEX_BITMAP) {
// 首先不考虑run.content中的位图大小,来计算一下nvalues
size_t content_size = (*size_idx) * CHUNKSIZE - sizeof(struct chunk_run_header);
b->nbits = (unsigned)(content_size / unit_size);
// calculate the number of "values".
b->nvalues = (b->nbits + RUN_BITS_PER_VALUE - 1) / RUN_BITS_PER_VALUE;
// 为了保证在对齐时保持cacheline对齐,nvalues的计算需要包括chunk_run_header所占用的空间
b->nvalues = ALIGN_UP( \
b->nvalues + sizeof(struct chunk_run_header) / sizeof(uint64_t), \ // size
(CACHELINE_SIZE / sizeof(*b->values))) \ // alignment
- sizeof(struct chunk_run_header) / sizeof(uint64_t)
// 计算在chunk中的位图所占用的内存大小
b->size = b->nvalues * sizeof(*b->values);
// 减去run中位图以及对齐的大小,再次重新将计算allocations的数量
b->nbits = (unsigned)((content_size - b->size) / unit_size)
- (alignment ? 1U : 0U);
// 最后一步需要计算在位图的结尾有多少空间是用来对齐了
unsigned unused_bits = (b->nvalues * RUN_BITS_PER_VALUE)
- b->nbits;
unsigned unused_values = unused_bits / RUN_BITS_PER_VALUE;
b->nvalues -= unused_values;
// b->values 指向chunk_run中的位图
b->values = (uint64_t *)content;
return;
}
// ....
}
/* runtime bitmap information for a run */
struct run_bitmap {
unsigned nvalues; // values数组的长度,只是用来保证数据能与cacheline对齐
unsigned nbits; // run中blocks的数量,block的大小就是对应分配类的unitsize
size_t size; // 位图的大小
uint64_t *values; // 指向run中存放data的部分
};
桶bucket_locked
在libpmemobj中提出了一个名为arena的概念,每个试图申请内存的线程都会找到一个arena,后续就在这个arena中进行内存的管理,arena的数量跟系统中处理器核心个数一致:
int
heap_boot(struct palloc_heap *heap, void *heap_start, uint64_t heap_size,
uint64_t *sizep, void *base, struct pmem_ops *p_ops,
struct stats *stats, struct pool_set *set)
{
// ...
unsigned narenas_default = Default_arenas_max == 0 ?
heap_get_procs() : (unsigned)Default_arenas_max;
heap_arenas_init(&h->arenas);
// ...
for (unsigned i = 0; i < narenas_default; ++i)
VEC_PUSH_BACK(&h->arenas.vec, heap_arena_new(heap, 1))
}
/*
* heap_arena_new -- (internal) initializes arena instance
*/
static struct arena *
heap_arena_new(struct palloc_heap *heap, int automatic)
{
struct heap_rt *rt = heap->rt;
arena->nthreads = 0;
arena->automatic = automatic;
arena->arenas = &heap->rt->arenas;
for (uint8_t i = 0; i < MAX_ALLOCATION_CLASSES; ++i) {
struct alloc_class *ac = alloc_class_by_id(rt->alloc_classes, i);
if (ac != NULL)
arena->buckets[i] = bucket_locked_new(container_new_seglists(heap), ac);
else arena->buckets[i] = NULL;
}
return arena;
}
每个arena中有很多的桶bucket_locked,在分配内存的时候,可以通过bucket_locked来快速索引持久内存块。可以看到arena中的桶的数量跟分配类数组是一致的,每个桶中索引的内存块是不一样的,这应该跟分配类相关。
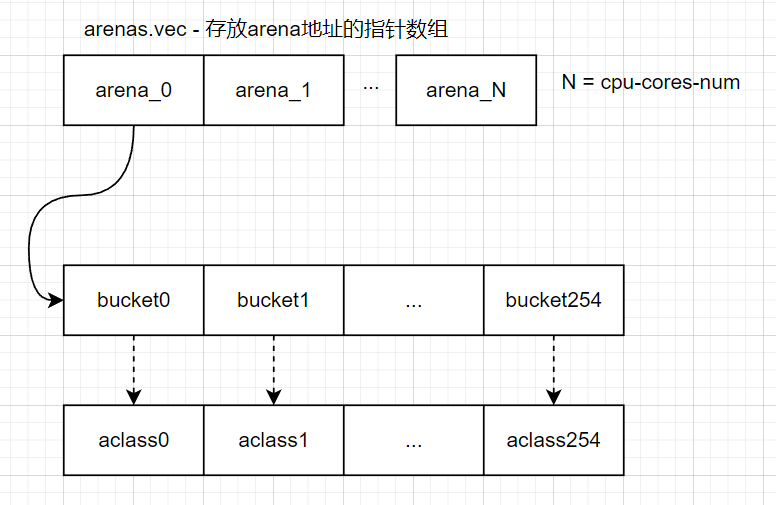
下面是bucket_locked结构体的成员变量,其中最重要的一个成员变量应该是 block_container:
struct bucket_locked {
struct bucket bucket;
os_mutex_t lock;
};
struct bucket {
/* this struct is both the lock guard and the locked state */
struct bucket_locked *locked;
struct alloc_class *aclass;
struct block_container *container;
const struct block_container_ops *c_ops;
struct memory_block_reserved *active_memory_block;
int is_active;
};
bucket_container有两种形式:block_container_ravl、block_container_seglists。只有default_bucket(bucket[0])的容器是ravl-tree,其余的都是seglists。前面说到过分配内存的时候可以通过桶来快速索引内存块memory_block,实际上是通过桶中的容器ravl或者是seglists。
另外,进程要认识到桶中是否有可用的内存,是通过桶中的成员变量is_active以及active_memory_block来识别的。下面是active_memory_block这个成员变量的定义:
/*
* This is a representation of a run memory block that is active in a bucket or
* is on a pending list in the recycler.
* This structure should never be passed around by value because the address of
* the nresv variable can be in reservations made through palloc_reserve(). Only
* if the number of reservations equals 0 the structure can be moved/freed.
*/
struct memory_block_reserved {
struct memory_block m;
struct bucket_locked *bucket;
/*
* Number of reservations made from this run, the pointer to this value
* is stored in a user facing pobj_action structure. Decremented once
* the reservation is published or canceled.
*/
int nresv;
};
nresv这个成员变量的含义我到现在还不太确定,我猜是表示这个内存块中一共有多少个线程在使用。假如现在reservation的数量是0,就说明这个内存块中的block全部可用,那么就设置empty标签标识这个内存块空闲。
seglist如何管理block
在非默认桶中管理units使用的是分段列表(segregated lists),总体来说分为插入/删除两种操作。所谓分段列表实际上就是根据不同的块大小将内存块分类存储。每个列表对应特定大小范围的内存块,这样在分配内存时,可以根据所需大小快速找到最适合的块,从而减少内存浪费和碎片化,例如在Linux中用伙伴系统(buddy system)管理空闲的连续物理内存,底层实现就是分段链表。

下面是block_container_seglists的初始化,可以看到初始化bucket其实就是初始化了一个分段列表block_container_seglists。
struct block_container_seglists {
struct block_container super;
struct memory_block m;
struct {
uint32_t *buffer;
size_t capacity; // buffer数组的长度
size_t front; // buffer数组中首个元素下标
size_t back; // buffer数组的末尾下标
} blocks[SEGLIST_BLOCK_LISTS];
/* 表示哪些大小类别中有可用的块的位图 */
uint64_t nonempty_lists;
};
/*
* bucket_locked_new -- creates a new locked bucket instance
*/
struct bucket_locked *
bucket_locked_new(struct block_container *c, struct alloc_class *aclass)
{
struct bucket_locked *b = Malloc(sizeof(*b));
bucket_init(&b->bucket, c, aclass);
b->bucket.locked = b;
return b;
}
/*
* container_new_seglists -- allocates and initializes a seglists container
*/
struct block_container *
container_new_seglists(struct palloc_heap *heap)
{
struct block_container_seglists *bc = Malloc(sizeof(*bc));
bc->super.heap = heap;
bc->super.c_ops = &container_seglists_ops;
// #define SEGLIST_BLOCK_LISTS 64U
for (unsigned i = 0; i < SEGLIST_BLOCK_LISTS; ++i) {
do {
bc->blocks[i].buffer = NULL;
bc->blocks[i].capacity = 0;
bc->blocks[i].front = 0;
bc->blocks[i].back = 0;
} while (0)
}
bc->nonempty_lists = 0;
/* super - bc中的第一个成员变量 */
return (struct block_container *)&bc->super;
}
可以看到桶中的内存块memblock按照分配类的unit_size被划分成了很多个小块,这些小块就是由block_container_seglists 这个结构体进行组织管理的。
这里一下面这张图举例解释一下blocks数组的用处。
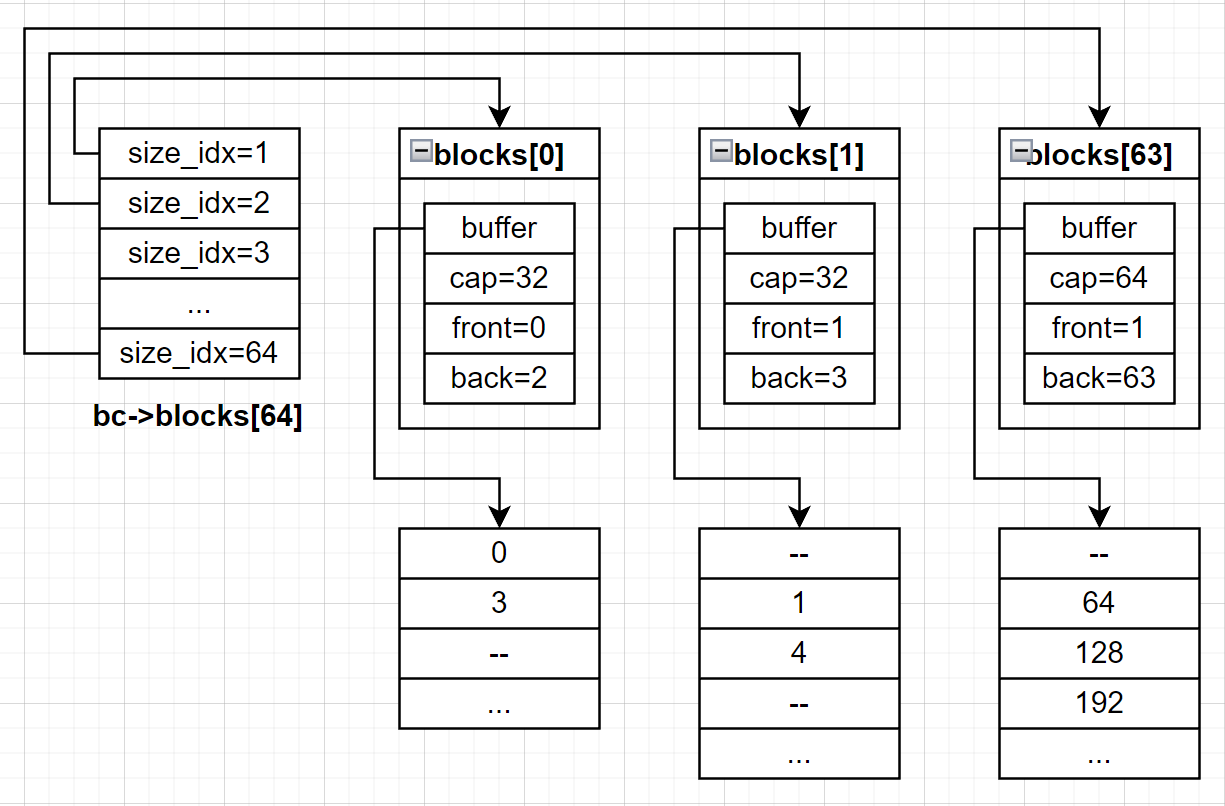
blocks数组的下标为 i 表示存放在blocks中的每个块都是由 i+1 个连续的unit组成。例如blocks[0]中存放每个块的大小都是unisize*(0+1),blocks[63]中的每个块的大小都是unitsize*63+1。
buffer指向了一个数组,数组中的val表示块对应的位在位图中的偏移量,再加上前面说的blocks下标的意义,buffer数组中的每个元素都唯一标识了run中的一个块。
front和back是用来维护buffer循环队列的下标,front代表从哪里取下一个可用的块;back代表下一个块应该被放入的位置。
不要忘记了block_container是在DRAM中的,只是用于记录内存池中有哪些可用的块,已经分配出去的块它是不会管的。就算进程重启,进程也可以通过定位run中的位图bitmap来快速重建block_container。
删除内存块
下面是在seglist中寻找内存块的代码:
/*
* container_seglists_get_rm_block_bestfit -- (internal) removes and returns the
* best-fit memory block for size
*/
static int
container_seglists_get_rm_block_bestfit(struct block_container *bc,
struct memory_block *m)
{
struct block_container_seglists *c = (struct block_container_seglists *)bc;
ASSERT(m->size_idx <= SEGLIST_BLOCK_LISTS);
uint32_t i = 0;
/*
* applicable lists
* 位掩码,表示比请求大小更小的内存块列表,举个例子:
* 假设 size_idx = 5,那么得到size_mask = 0b1111,
* 表示size_idx=1,2,3,4的类别,它们的块大小不适合分配给请求大小
*/
uint64_t size_mask = (1ULL << (m->size_idx - 1)) - 1;
/*
* 对 nonempty_lists 和 size_mask 做按位与操作,过滤掉所有比请求大小更小的列表
* 只保留那些大小等于或大于请求的非空列表。
*/
uint64_t v = c->nonempty_lists & ~size_mask;
if (v == 0) return ENOMEM;
/* finds the list that serves the smallest applicable size */
i = (unsigned char)__builtin_ctzll(v);
uint32_t block_offset = c->blocks[i].buffer[ \
(c->blocks[i].front ++) & \
(c->blocks[i].capacity - 1) \
];
/* marks the list as empty */
if (c->blocks[i].back - c->blocks[i].front == 0)
c->nonempty_lists &= ~(1ULL << (i));
*m = c->m;
m->block_off = block_offset;
m->size_idx = i + 1;
return 0;
}
从代码中获取buffer下标的操作可以看出,buffer实际上是一个环形队列,(front++) & (capacity - 1)就是为了确保当front达到capacity之后会被重置到0,从而实现循环访问。
现在来假设一组数据来看一下具体的过程。假设刚开始的输入数据如下:
struct block_container_seglists bc;
bc.nonempty_lists = 0b1011;
m->size_idx = 2;
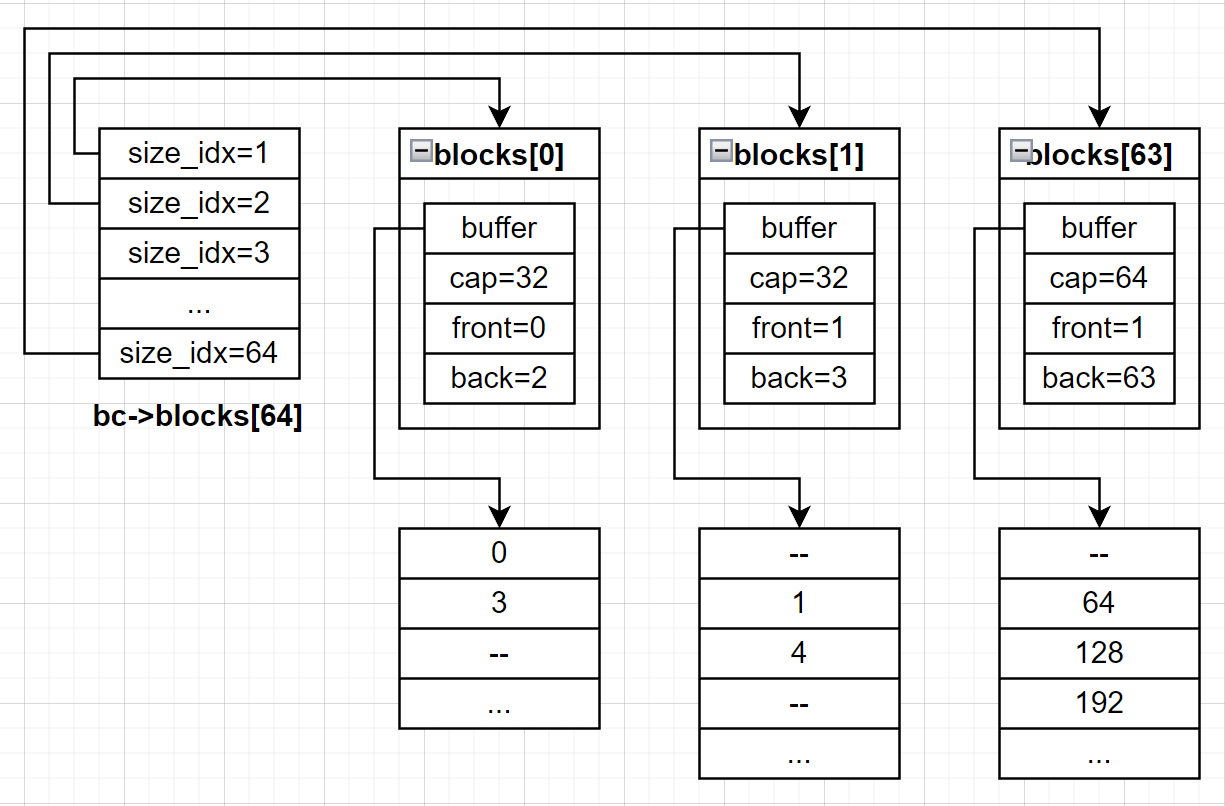
首先通过size_idx计算size_mask和v,从而得出这个桶中有两个列表(blocks[1] 和 blocks[3])可以提供合适的内存块
size_mask = 0b1 -> This mask filters out smaller sizes (size_idx = 1).
v = nonempty_lists & ~size_mask
= 0b1011 & 0b1110
= 0b1010 -> Lists: [1, 3] are suitable (size_idx >= 2).
这里通过gcc内联函数__builtin_ctzll(v)找到了第一个合适的非空列表blocks[1]
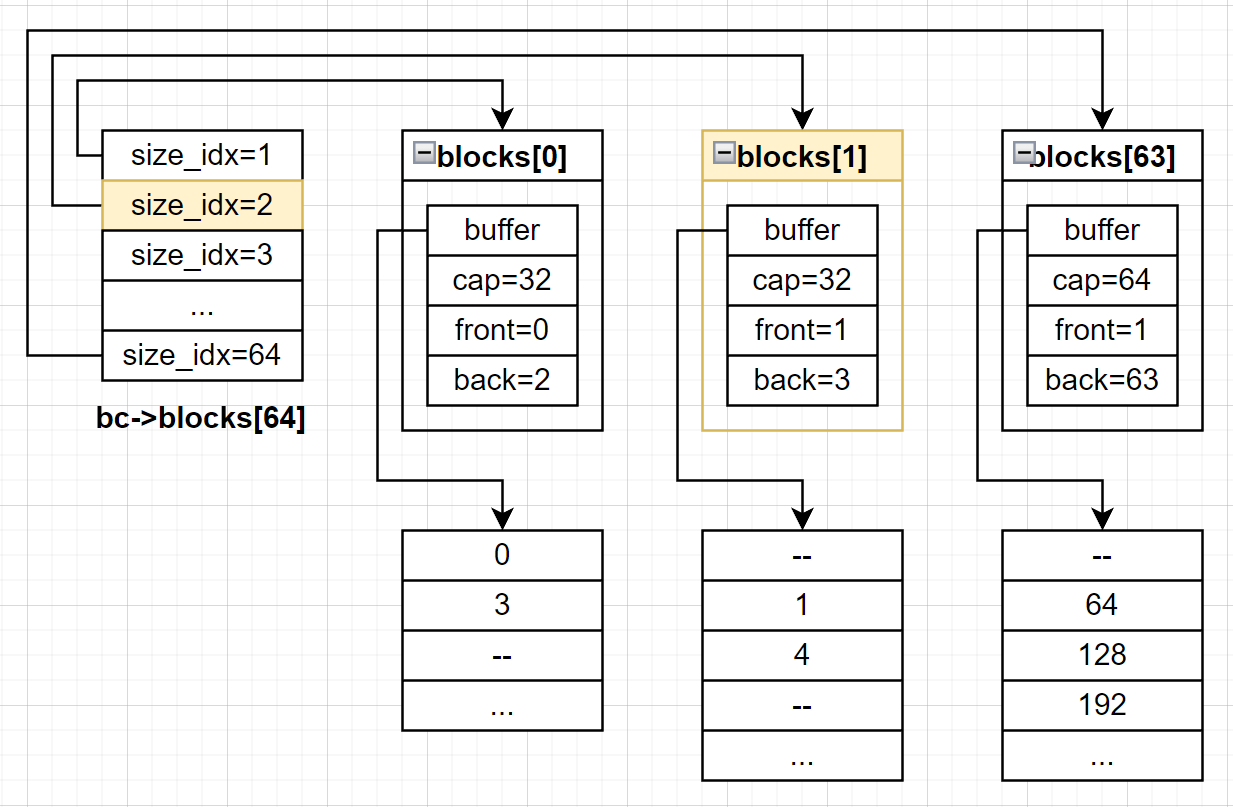
接下来我们从blocks[1]中取出首个内存块,并更新front:
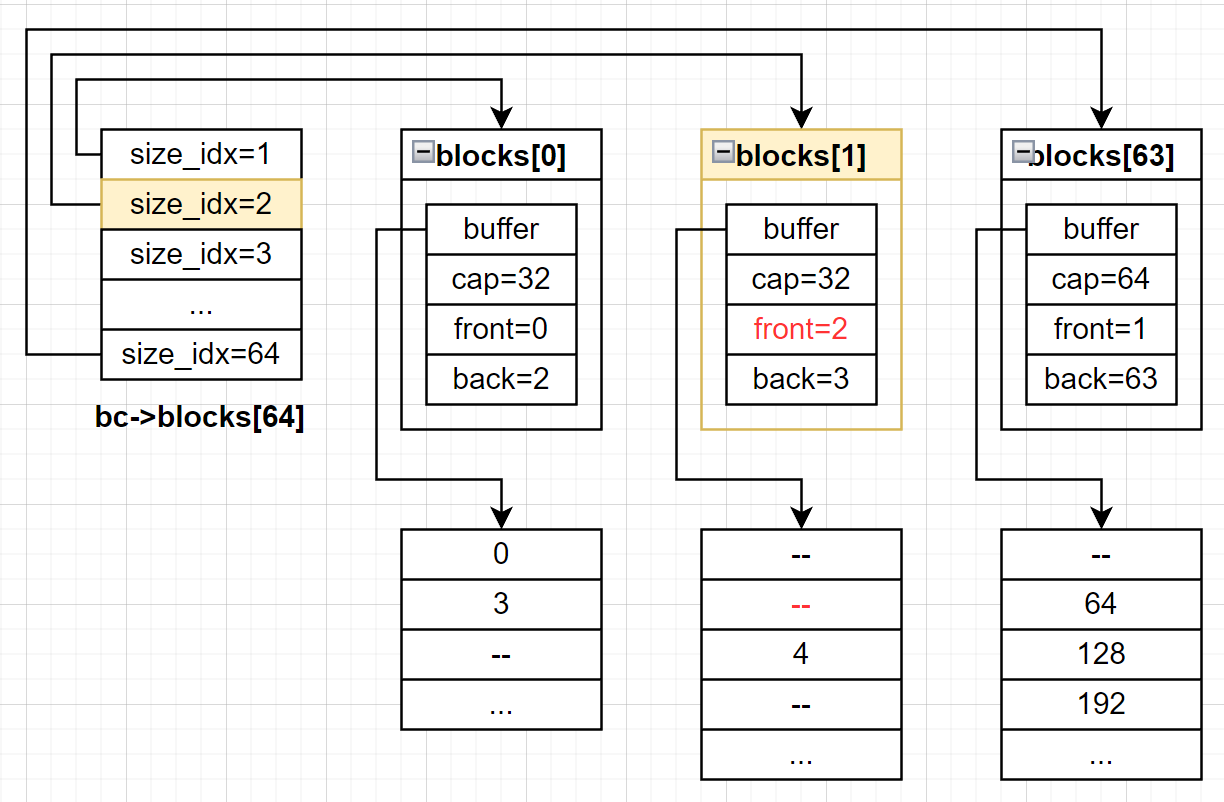
接下来需要检查blocks[1]在取出内存块之后是否为空,如果为空就需要将位图更新一下,这里是不为空的,因此不用做任何处理。
最后需要更新一下待返回的memblock为下面的状态,待返回的内存块这样就算找到了:
*m = c->m;
m->block_off = block_offset;
m->size_idx = i + 1;
插入内存块
下面是插入内存块到桶中的相关代码:
/*
* cb = bucket_memblock_insert_block
* --> container_seglists_insert_block
* 将内存块插入到 bucket 的 seglists 中
*/
static int
container_seglists_insert_block(struct block_container *bc,
const struct memory_block *m)
{
ASSERT(m->chunk_id < MAX_CHUNK);
ASSERT(m->zone_id < UINT16_MAX);
ASSERTne(m->size_idx, 0);
struct block_container_seglists *c =
(struct block_container_seglists *)bc;
if (c->nonempty_lists == 0)
c->m = *m;
ASSERT(m->size_idx <= SEGLIST_BLOCK_LISTS);
ASSERT(m->chunk_id == c->m.chunk_id);
ASSERT(m->zone_id == c->m.zone_id);
// 选中需要插入的内存块对应在seglists中的blocks数组元素
if (VECQ_ENQUEUE(&c->blocks[m->size_idx - 1], m->block_off) != 0)
return -1;
// 将nonempty_lists位图中对应的队列改为非空的状态
c->nonempty_lists |= 1ULL << (m->size_idx - 1);
return 0;
}
/*
* vec = c->blocks[m->size_idx - 1]
* element = m->block_off
*/
#define VECQ_ENQUEUE(vec, element)\
((vec)->capacity == VECQ_SIZE(vec) ?\
(VECQ_GROW(vec) == 0 ? VECQ_INSERT(vec, element) : -1) :\
VECQ_INSERT(vec, element))
/*
* 如果当前capacity为0,则初始化为64,否则将capacity加倍
* 调整容量之后尝试用realloc重新分配内存
* 将现有元素移动到新内存的正确位置
* 更新front、back、capacity
*/
#define VECQ_GROW(vec)\
(realloc_set((void **)&(vec)->buffer,\
VECQ_NCAPACITY(vec) * sizeof(*(vec)->buffer)) ? -1 :\
(memcpy((vec)->buffer + (vec)->capacity, (vec)->buffer,\
VECQ_FRONT_POS(vec) * sizeof(*(vec)->buffer)),\
(vec)->front = VECQ_FRONT_POS(vec),\
(vec)->back = (vec)->front + (vec)->capacity,\
(vec)->capacity = VECQ_NCAPACITY(vec),\
0\
))
// 将block_off插入到队列中
#define VECQ_INSERT(vec, element)\
(VECQ_BACK(vec) = element, (vec)->back += 1, 0)
假设一组数据来模拟插入的过程,假设初始状态如下:
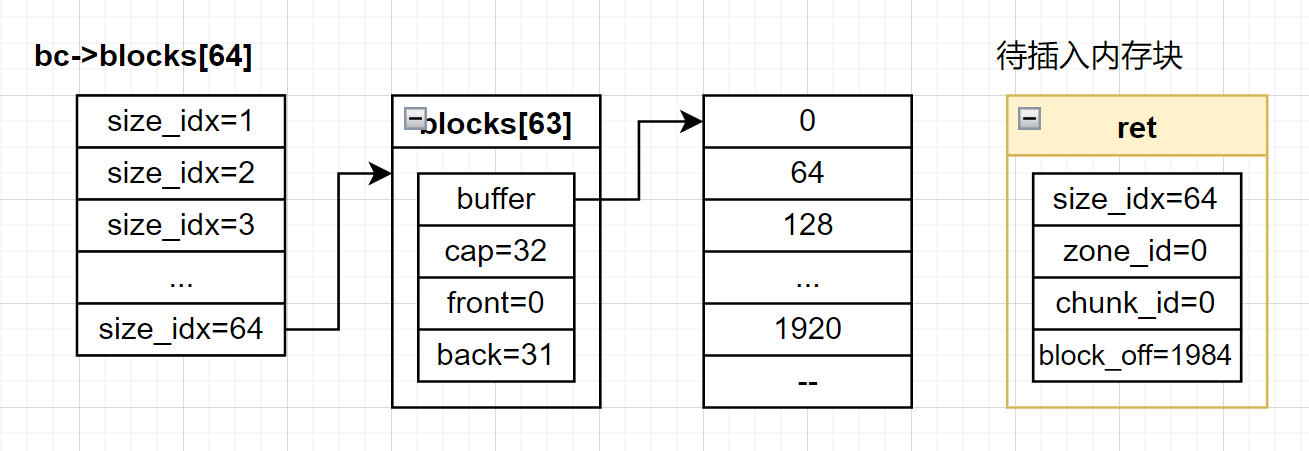
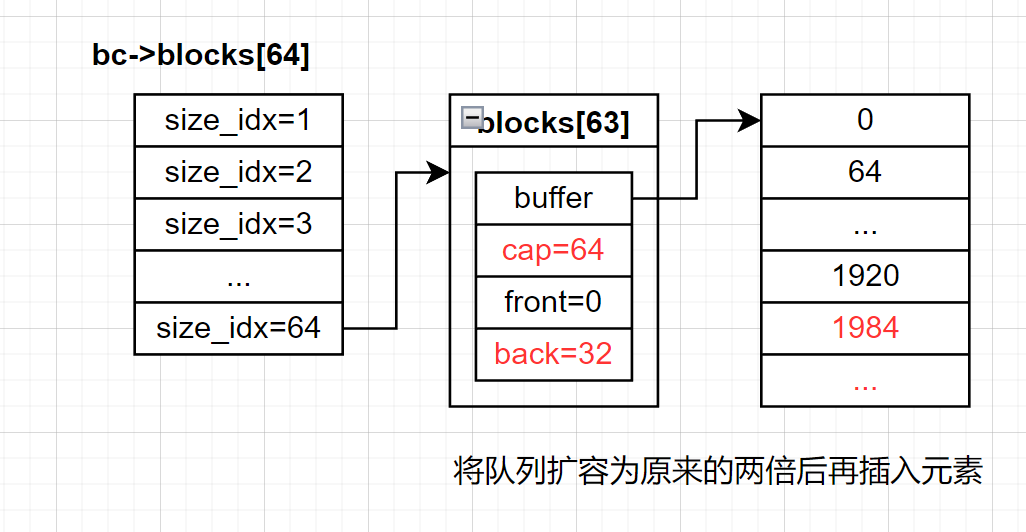
现在我们尝试插入新元素,在检查容量时发现队列已满,这时候就需要调用realloc将原本的blocks数组进行扩容,扩容完之后,将原来blocks数组中的数据迁移到新的blocks数组,并插入新内存块的block_off。
内存池中root对象的分配
root对象是用户访问内存池内的用户数据的入口,一个内存池中就只会存在一个root对象,下面来看一下root对象是如何被分配的,它为什么能够作为用户访问数据的入口。
1、寻找最佳分配类
在分配对象之前首先需要确定最佳适配待分配对象的分配类,下面的代码就是具体的过程,寻找适配分配类的过程就是遍历所有可能的分配类,然后找到内存碎片最小的方案。
/*
* alloc_class_assign_by_size -- (internal) chooses the allocation class that
* best approximates the provided size
*/
static struct alloc_class *
alloc_class_assign_by_size(struct alloc_class_collection *ac,
size_t size)
{
size_t class_map_index = 1 + (size-1)/ac->granularity;
// class_map_index * ac->granularity >= size 预留一部分内存防止内存越界
struct alloc_class *c = alloc_class_find_min_frag(ac,
class_map_index * ac->granularity);
/*
* We don't lock this array because locking this section here and then
* bailing out if someone else was faster would be still slower than
* just calculating the class and failing to assign the variable.
* We are using a compare and swap so that helgrind/drd don't complain.
*/
util_bool_compare_and_swap64(
&ac->class_map_by_alloc_size[class_map_index],
MAX_ALLOCATION_CLASSES, c->id);
return c;
}
/*
* alloc_class_find_min_frag -- searches for an existing allocation
* class that will provide the smallest internal fragmentation for the given
* size.
*/
static struct alloc_class *
alloc_class_find_min_frag(struct alloc_class_collection *ac, size_t n)
{
struct alloc_class *best_c = NULL;
size_t lowest_waste = SIZE_MAX;
/*
* Start from the largest buckets in order to minimize unit size of
* allocated memory blocks.
*/
for (int i = MAX_ALLOCATION_CLASSES - 1; i >= 0; --i) {
struct alloc_class *c = ac->aclasses[i];
/* can't use alloc classes /w no headers by default */
if (c == NULL || c->header_type == HEADER_NONE)
continue;
size_t real_size = n + header_type_to_size[c->header_type];
/*
* units >= real_size 预留一部分内存防止内存越界
* units 表示分配对象(real_size大小的块)所需要用到的unit数量
*/
size_t units = (real_size - 1) / c->unit_size + 1;
/* can't exceed the maximum allowed run unit max (8)*/
if (c->type == CLASS_RUN && units > RUN_UNIT_MAX_ALLOC)
continue;
if (c->unit_size * units == real_size)
return c;
// else c->unit_size * units > real_size
size_t waste = (c->unit_size * units) - real_size;
if (c->type == CLASS_RUN) {
/*
* 假设后面都只分配这种对象了,会浪费掉wasted_units个unit
*/
size_t wasted_units = c->rdsc.nallocs % units;
size_t wasted_bytes = wasted_units * c->unit_size;
size_t waste_avg_per_unit = wasted_bytes / c->rdsc.nallocs;
waste += waste_avg_per_unit;
}
if (best_c == NULL || lowest_waste > waste) {
best_c = c;
lowest_waste = waste;
}
}
return best_c;
}
2、根据分配类寻找桶
在找到最佳适配的分配类之后,接下来需要到arena数组arenas.vec中找到一个最少使用的arena,然后将其与当前线程进行绑定,然后到这个arena中寻找最佳适配的桶bucket,下面是相关的代码:
/*
* heap_bucket_acquire -- fetches by arena or by id a bucket exclusive
* for the thread until heap_bucket_release is called
*/
struct bucket *
heap_bucket_acquire(struct palloc_heap *heap, uint8_t class_id,
uint16_t arena_id)
{
struct heap_rt *rt = heap->rt;
struct bucket_locked *b;
// ...
if (arena_id == HEAP_ARENA_PER_THREAD) {
struct arena *arena = heap_thread_arena(heap);
ASSERTne(arena->buckets, NULL);
b = arena->buckets[class_id];
} else // ...
out:
return bucket_acquire(b);
}
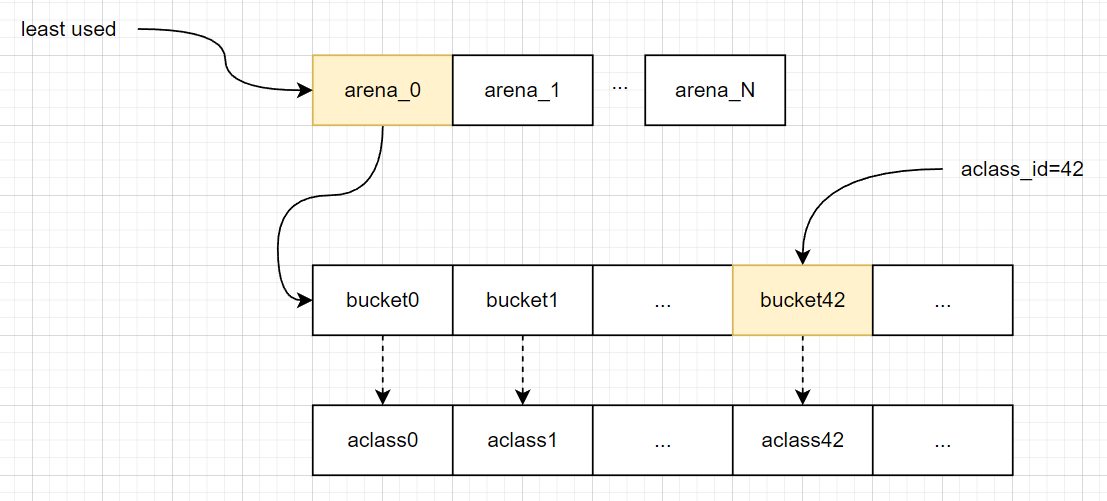
3、填充内存块到默认桶
在确定好bucket之后,就要到这个桶中寻找最佳适配的内存块mem_block,但是刚开始桶是空的没有填充内存块,因此后面会尝试各种工作来填充内存块到确定好的bucket中。但是由于这是第一个申请的对象,因此这些工作都会失败。
接下来会尝试填充default_bucket,下面是相关的代码:
/*
* heap_ensure_run_bucket_filled -- (internal) refills the bucket if needed
*/
static int
heap_ensure_run_bucket_filled(struct palloc_heap *heap, struct bucket *b,
uint32_t units)
{
struct alloc_class *aclass = bucket_alloc_class(b);
ASSERTeq(aclass->type, CLASS_RUN);
int ret = 0;
heap_detach_and_try_discard_run(heap, b);
if (heap_reuse_from_recycler(heap, b, units, 0) == 0)
goto out;
/**
* search in the next zone before attempting to create a new run
*
* 切换到default_bucket中,尝试填充这个桶:
* 首先选中堆中首个可用的区域zone,然后初始化这个区域,工作包括
* - 计算堆中第zone_id个区域共有多少个CHUNKSIZE大小的块,记录到size_idx中
* - 为该区域新建一个memblock,size_idx就是区域中的CHUNKSIZE块数量
* - 将这个memblock内存块插入到bucket中
*/
struct bucket *defb = heap_bucket_acquire(heap,
DEFAULT_ALLOC_CLASS_ID,
HEAP_ARENA_PER_THREAD);
heap_populate_bucket(heap, defb);
// ...
}
和前面的非默认桶不一样的是,非默认桶管理元素使用的是分离列表,而默认桶管理元素使用的是ravl-tree,有关ravl-tree的介绍可以参考这篇论文:https://sidsen.azurewebsites.net//papers/ravl-trees-journal.pdf
memory_block是有两种类型的,分别是memory_block_run、memory_block_huge,前者中size_idx是表示分配内存要是unit_size的倍数,后者中的size_idx是表示分配内存要是CHUNKSIZE的倍数。
然后还有一点要注意的就是heap_detach_and_try_discard_run这个函数,调用这个函数就说明当前桶中的活跃块(chunk_run)已经使用完了,那么就会调用heap_detach_and_try_discard_run这个函数将会把当前桶中的活跃块disable掉,并将这个块的定位信息插入到与桶对应的回收器recycler中。后续在内存池中实在没有可用的空间了那么就会触发回收器尝试回收这些disable掉的块,下面是这个函数的相关代码:
/*
* heap_discard_run -- puts the memory block back into the global heap.
*/
void
heap_discard_run(struct palloc_heap *heap, struct memory_block *m)
{
if (heap_reclaim_run(heap, m, 0)) {
struct bucket *b = heap_bucket_acquire(heap, DEFAULT_ALLOC_CLASS_ID, 0);
/*
* 假如在查看内存块位图的过程中发现原先在桶中的活跃内存块中的unit已经全部被释放掉了
* 那么就会将这个块以及相邻的类型为"CHUNK_TYPE_FREE"的内存块合并
* 然后将其转换成HUGE_BLOCK然后插入到默认桶中
*/
heap_run_into_free_chunk(heap, b, m);
heap_bucket_release(b);
}
}
/*
* heap_reclaim_run -- checks the run for available memory if unclaimed.
*
* Returns 1 if reclaimed chunk, 0 otherwise.
*/
static int
heap_reclaim_run(struct palloc_heap *heap, struct memory_block *m, int startup)
{
struct chunk_run *run = heap_get_chunk_run(heap, m);
struct chunk_header *hdr = heap_get_chunk_hdr(heap, m);
struct alloc_class *c = alloc_class_by_run(
heap->rt->alloc_classes,
run->hdr.block_size, hdr->flags, m->size_idx);
struct recycler_element e = recycler_element_new(heap, m);
if (e.free_space == c->rdsc.nallocs)
return 1;
struct recycler *recycler = heap_get_recycler(heap, c->id,
c->rdsc.nallocs);
// 将disable掉的内存块定位信息插入到recycler中
if (recycler != NULL) recycler_put(recycler, e);
return 0;
}
4、从默认桶中寻找所需内存块
在填充了一个memblock内存块到default_bucket的ravl-tree中之后,就会在default_bucket中获取分配内存所需要的内存块,下面是相关的代码:
/*
* heap_ensure_run_bucket_filled -- (internal) refills the bucket if needed
*/
static int
heap_ensure_run_bucket_filled(struct palloc_heap *heap, struct bucket *b,
uint32_t units)
{
// ...
struct memory_block m = MEMORY_BLOCK_NONE;
m.size_idx = aclass->rdsc.size_idx;
// 获取到 default_bucket
defb = heap_bucket_acquire(heap,
DEFAULT_ALLOC_CLASS_ID,
HEAP_ARENA_PER_THREAD);
/*
* cannot reuse an existing run, create a new one
*/
if (heap_get_bestfit_block(heap, defb, &m) == 0) {
ASSERTeq(m.block_off, 0);
if (heap_run_create(heap, b, &m) != 0) {
heap_bucket_release(defb);
return ENOMEM;
}
heap_bucket_release(defb);
goto out;
}
// ...
}
首先第一步是到default_bucket中找到一个满足分配条件的块,下面是相关的代码:
/*
* heap_ensure_run_bucket_filled -- (internal) refills the bucket if needed
*/
static int
heap_ensure_run_bucket_filled(struct palloc_heap *heap, struct bucket *b,
uint32_t units)
{
// ...
/* cannot reuse an existing run, create a new one */
if (heap_get_bestfit_block(heap, defb, &m) == 0) {
ASSERTeq(m.block_off, 0);
if (heap_run_create(heap, b, &m) != 0) {
heap_bucket_release(defb);
return ENOMEM;
}
heap_bucket_release(defb);
goto out;
}
heap_bucket_release(defb);
if (heap_reuse_from_recycler(heap, b, units, 0) == 0)
goto out;
ret = ENOMEM;
out:
return ret;
}
/*
* heap_get_bestfit_block --
* extracts a memory block of equal size index
*/
int
heap_get_bestfit_block(struct palloc_heap *heap, struct bucket *b,
struct memory_block *m)
{
struct alloc_class *aclass = bucket_alloc_class(b);
uint32_t units = m->size_idx; // m->size_idx == 1
// 从default_bucket中找到所需要的内存块并保存到m中
while (bucket_alloc_block(b, m) != 0) {/*...*/}
ASSERT(m->size_idx >= units); // m->size_idx == 17
if (units != m->size_idx)
heap_split_block(heap, b, m, units);
m->m_ops->ensure_header_type(m, aclass->header_type);
m->header_type = aclass->header_type;
return 0;
}
int bucket_alloc_block(struct bucket *b, struct memory_block *m_out)
{
// b->container.get_rm_bestfit = container_ravl_get_rm_block_bestfit
return b->c_ops->get_rm_bestfit(b->container, m_out);
}
/*
* container_ravl_get_rm_block_bestfit -- (internal) removes and returns the
* best-fit memory block for size
*/
static int
container_ravl_get_rm_block_bestfit(struct block_container *bc,
struct memory_block *m)
{
struct block_container_ravl *c = (struct block_container_ravl *)bc;
struct ravl_node *n = ravl_find(c->tree, m, RAVL_PREDICATE_GREATER_EQUAL);
if (n == NULL) return ENOMEM;
struct memory_block *e = ravl_data(n);
*m = *e;
ravl_remove(c->tree, n);
return 0;
}
在刚开始从ravl-tree中寻找节点的时候需要指定一个期望的将结果,这里期望的结果是RAVL_PREDICATE_GREATER_EQUAL,表示希望能找到一个最佳节点中的内存是大于等于所需内存,同时是小于所有其他满足上一个条件的节点,假如所需要的节点,还需要将其从树中移除掉。
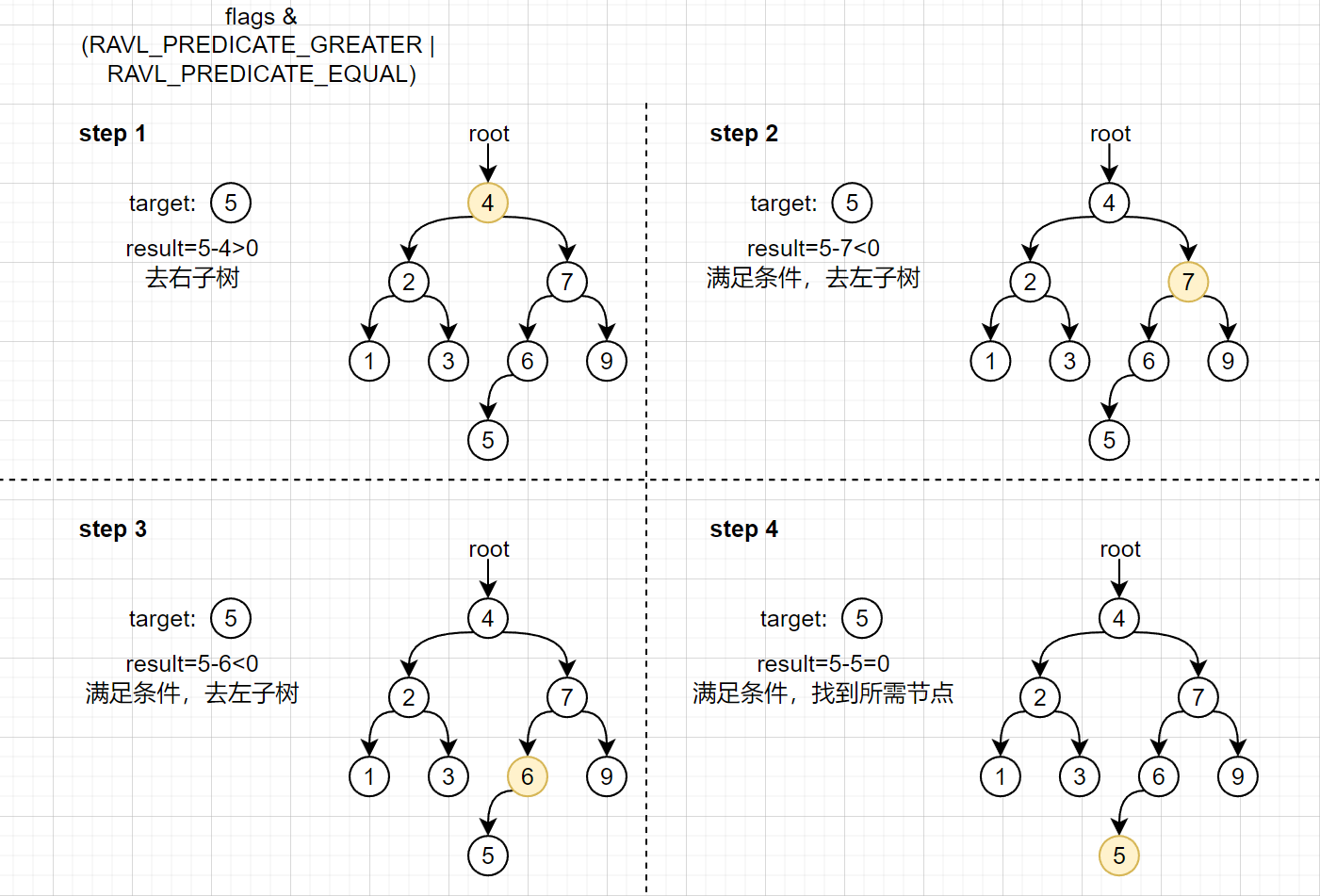
由于前面已经填充过default_bucket了,因此这一次肯定是可以找到的。接下来需要对找到的这个内存块进行裁剪,只需要取出分配内存所需要的块大小,内存块中剩余的部分需要重新插回到default_bucket中,下面是相关的代码:
int
heap_get_bestfit_block(struct palloc_heap *heap, struct bucket *b,
struct memory_block *m)
{
struct alloc_class *aclass = bucket_alloc_class(b);
uint32_t units = m->size_idx; // m->size_idx == 1
// 从default_bucket中找到所需要的内存块并保存到m中
while (bucket_alloc_block(b, m) != 0) {/*...*/}
ASSERT(m->size_idx >= units); // m->size_idx == 17
// 对找到的内存块进行裁切
if (units != m->size_idx)
heap_split_block(heap, b, m, units);
m->m_ops->ensure_header_type(m, aclass->header_type);
m->header_type = aclass->header_type;
return 0;
}
/*
* heap_split_block -- (internal) splits unused part of the memory block
*/
static void
heap_split_block(struct palloc_heap *heap, struct bucket *b,
struct memory_block *m, uint32_t units)
{
struct alloc_class *aclass = bucket_alloc_class(b);
ASSERT(units <= UINT16_MAX);
ASSERT(units > 0);
if (aclass->type == CLASS_RUN) {
ASSERT((uint64_t)m->block_off + (uint64_t)units <= UINT32_MAX);
struct memory_block r = {m->chunk_id, m->zone_id,
m->size_idx - units, (uint32_t)(m->block_off + units),
NULL, NULL, 0, 0, NULL};
memblock_rebuild_state(heap, &r);
bucket_insert_block(b, &r);
} else {
uint32_t new_chunk_id = m->chunk_id + units;
uint32_t new_size_idx = m->size_idx - units;
struct memory_block n = memblock_huge_init(heap,
new_chunk_id, m->zone_id, new_size_idx);
*m = memblock_huge_init(heap, m->chunk_id, m->zone_id, units);
bucket_insert_block(b, &n);
}
m->size_idx = units;
}
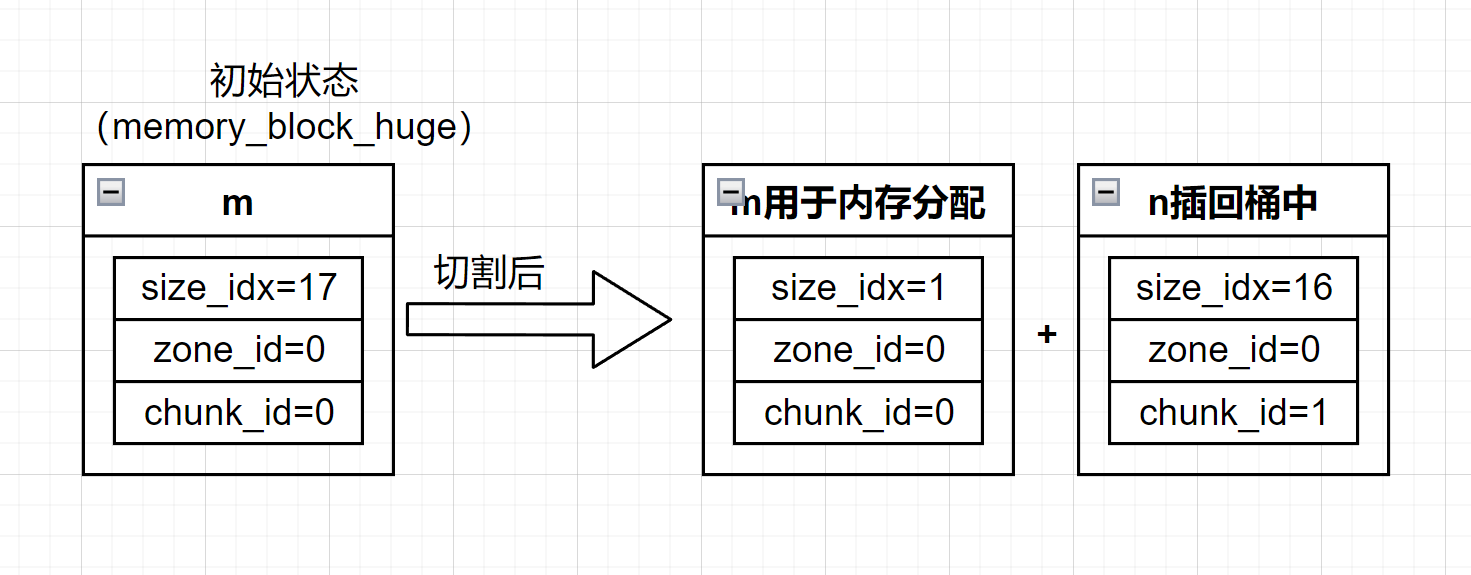
4.1、假如默认桶中没有内存怎么办
5、创建新的memory_block_run
接下来要在这个用于对象分配的内存块中创建run了,首先是将给定的内存块memblock初始化成MEMORY_BLOCK_RUN,这里用到了位图。
/*
* memblock_run_init -- initializes a new run memory block
*
* *m = memblock_run_init(heap, m->chunk_id, m->zone_id, &aclass->rdsc);
*/
struct memory_block
memblock_run_init(struct palloc_heap *heap,
uint32_t chunk_id, uint32_t zone_id, struct run_descriptor *rdsc)
{
uint32_t size_idx = rdsc->size_idx; // 1
ASSERTne(size_idx, 0);
// 待分割的memory_block
struct memory_block m = MEMORY_BLOCK_NONE;
m.chunk_id = chunk_id; // 0
m.zone_id = zone_id; // 0
m.size_idx = size_idx; // 1
m.heap = heap;
struct zone *z = ZID_TO_ZONE(heap->layout, zone_id);
// run = (struct chunk_run *)&ZID_TO_ZONE(layout, 0)->chunks[0]
struct chunk_run *run = heap_get_chunk_run(heap, &m);
// 这里runsize计算也是用到了size_idx,size_idx不一定是1
size_t runsize = sizeof(*run) + (size_idx - 1) * CHUNKSIZE;
run->hdr.block_size = rdsc->unit_size; // chunk_run 中的每个block都是unit_size
run->hdr.alignment = rdsc->alignment;
struct run_bitmap b = rdsc->bitmap; // 复制一份分配类中的位图保存到b中
b.values = (uint64_t *)run->content; // values会指向run中存放位图的地方
size_t bitmap_size = b.size; // 位图的大小(包括了padding)
memset(b.values, 0xFF, bitmap_size); // 将位图中的位全部标记为已用状态(1)
/* 将分配可用的位标记为可用状态(1) */
memset(b.values, 0, sizeof(*b.values) * (b.nvalues - 1));
unsigned trailing_bits = b.nbits % RUN_BITS_PER_VALUE; // 位图中最后一个value需要用到的位数
/*
* 如果 b.nbits 不是 64 的倍数,那么最后一个value中会有一些未使用的位。
* 这些未使用的位需要被标记为1,以防止它们被错误地分配。
* 虽然标记为1,但是这个部分的内存也是可用的,只要逆运算一下last_value就知道哪些bits是可用的了
*/
uint64_t last_value = UINT64_MAX << trailing_bits;
b.values[b.nvalues - 1] = last_value;
// 将chunk_run_header和位图刷新到持久化内存
pmemops_flush(&heap->p_ops, run,
sizeof(struct chunk_run_header) +
bitmap_size);
/*
* 对zone中的chunk_header数组中[chunk_id,chunk_id+size_idx]这个部分进行修改
* 假设内存块memblock的size_idx为4,那么数组中对应的部分的type、size_idx如下
* type - [RUN, RUN_DATA, RUN_DATA, RUN_DATA]
* size_idx - [4, 1, 2, 3] 其中size_idx[0]表示数组长度,后面的表示索引
*/
struct chunk_header run_data_hdr; // tmp for data_hdr
run_data_hdr.type = CHUNK_TYPE_RUN_DATA;
run_data_hdr.flags = 0;
struct chunk_header *data_hdr;
for (unsigned i = 1; i < size_idx; ++i) {
data_hdr = &z->chunk_headers[chunk_id + i];
run_data_hdr.size_idx = i;
*data_hdr = run_data_hdr;
}
pmemops_persist(&heap->p_ops,
&z->chunk_headers[chunk_id + 1],
sizeof(struct chunk_header) * (size_idx - 1));
struct chunk_header *hdr = &z->chunk_headers[chunk_id];
ASSERT(hdr->type == CHUNK_TYPE_FREE);
uint64_t run_hdr = chunk_get_chunk_hdr_value(CHUNK_TYPE_RUN,
rdsc->flags, hdr->size_idx);
util_atomic_store_explicit64((uint64_t *)hdr,
run_hdr, memory_order_relaxed);
pmemops_persist(&heap->p_ops, hdr, sizeof(*hdr));
/*
* 修改memblock中记录的元数据,最重要的是根据m中记录的chunk_id对应的chunk_type
* 将m->type会改成MEMORY_BLOCK_RUN
*/
memblock_rebuild_state(heap, &m);
m.cached_bitmap = &rdsc->bitmap;
return m;
}
原先从默认堆中取出来的内存块类型是MEMORY_BLOCK_HUGE,这个函数的作用就是将内存块类型改成MEMORY_BLOCK_RUN,并利用位图来定位内存块中的chunks的头部信息修改它们:
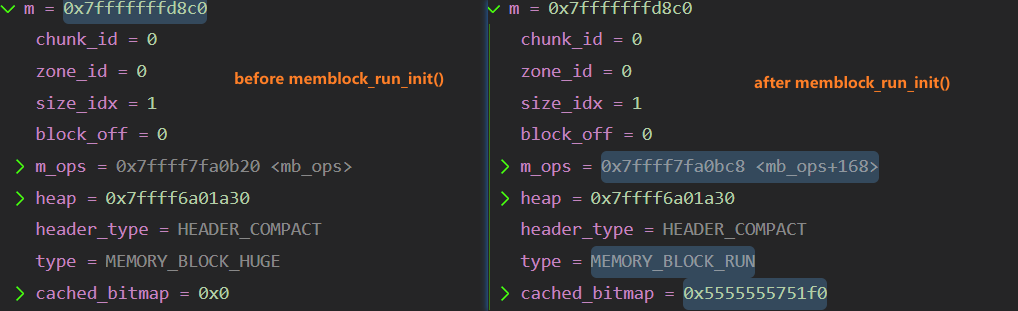
6、将memory_block_run附加到分配类指定的桶中
现在要将前面处理好的run内存块附加到桶中,表现形式就是为bucket_container_seglists中的buffer数组添加元素。
/*
* run_iterate_free -- 在run中迭代空闲blocks
*/
static int
run_iterate_free(const struct memory_block *m, object_callback cb, void *arg)
{
int ret = 0;
uint32_t block_off = 0;
struct run_bitmap b;
run_get_bitmap(m, &b); // m->cached_bitmap
struct memory_block nm = *m;
// bitmap中每64bits组成一个block,插入到桶中
for (unsigned i = 0; i < b.nvalues; ++i) {
uint64_t v = b.values[i]; // sizeof values[i] = 64bits
ASSERT((uint64_t)RUN_BITS_PER_VALUE * (uint64_t)i <= UINT32_MAX);
block_off = RUN_BITS_PER_VALUE * i; // 64 * i
ret = run_process_bitmap_value(&nm, v, block_off, cb, arg);
if (ret != 0)
return ret;
}
return 0;
}
/*
* heap_run_process_bitmap_value
* 查找values中未设置的bits,从中创建一个有效的内存块,并将该块插入到给定的桶中
*/
static int
run_process_bitmap_value(const struct memory_block *m,
uint64_t value, uint32_t base_offset, object_callback cb, void *arg)
{
int ret = 0;
uint64_t shift = 0; /* already processed bits */
struct memory_block s = *m;
do {
/*
* Shift the value so that the next memory block starts on the
* least significant position:
* ..............0 (free block)
* or ..............1 (used block)
*/
uint64_t shifted = value >> shift;
/* all clear or set bits indicate the end of traversal */
/*
* CASE 1
* 假如剩余的所有位都是0(可用块),则插入剩余的内存块并返回
*/
if (shifted == 0) {
/*
* Insert the remaining blocks as free. Remember that
* unsigned values are always zero-filled, so we must
* take the current shift into account.
*/
s.block_off = (uint32_t)(base_offset + shift);
s.size_idx = (uint32_t)(RUN_BITS_PER_VALUE - shift);
// 将内存块s插入到桶中,其实就是更改seglist中的blocks数组
if ((ret = cb(&s, arg)) != 0) return ret;
break;
}
/*
* CASE 2
* 假如剩余的所有位都是1(已经使用的块),则结束遍历
*/
else if (shifted == UINT64_MAX) break;
/*
* CASE 3
* 假如剩余的位不全为0,那么就更新shift
*
* 首先计算出剩余的内存块中第一个可用的块相对于剩余内存块的位置off
* 然后计算已经在剩余内存块中已经使用的块的大小size
*/
unsigned off = (unsigned)util_lssb_index64(~shifted);
unsigned size = (unsigned)util_lssb_index64(shifted);
shift += off + size;
/*
* 假如size为0说明剩余的内存块全是空闲的,就会到下一轮循环的CASE 1
* 否则说明有用过的内存块
*/
if (size != 0) { /* zero size means skip to the next value */
s.block_off = (uint32_t)(base_offset + (shift - size));
s.size_idx = (uint32_t)(size);
memblock_rebuild_state(m->heap, &s);
// 将内存块s插入到桶中
if ((ret = cb(&s, arg)) != 0)
return ret;
}
} while (shift != RUN_BITS_PER_VALUE);
return 0;
}
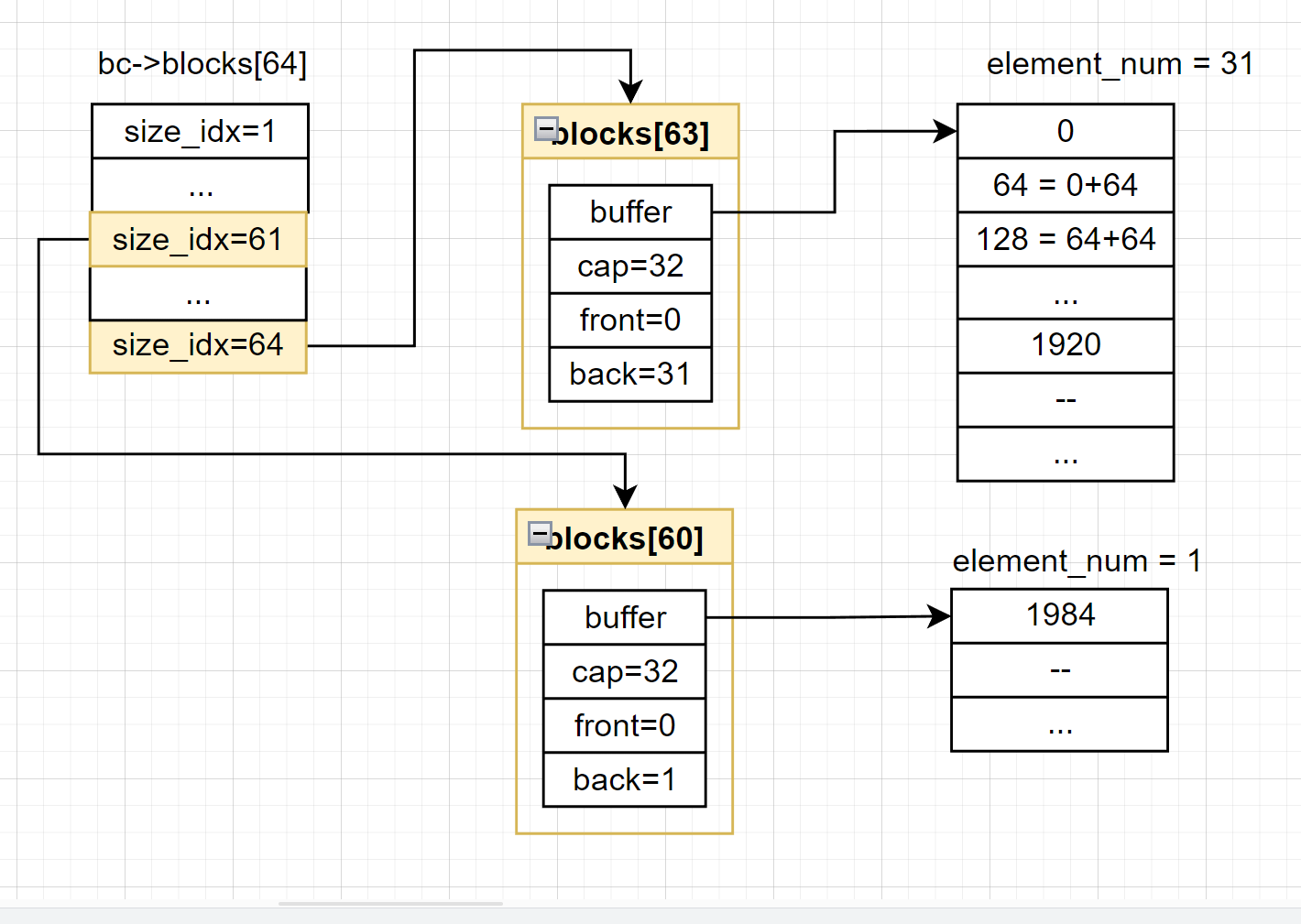
为什么图中会有两个blocks数组元素被插入?
记得在第五步中修改内存池中的位图的时候,位图中的最后一个value是赋了一个非零的值,但是这个部分的内存也是可用的,先回忆一下前面是怎么处理这最后一个value的:
unsigned trailing_bits = b.nbits % RUN_BITS_PER_VALUE;
uint64_t last_value = UINT64_MAX << trailing_bits;
b.values[b.nvalues - 1] = last_value;
最后的一个values实际上就是根据nbits来为UINT64_MAX进行左移操作,因此这里只需要逆运算一下就能算出trailing_bits,从而得出待插入的内存块的size_idx:
do {
uint64_t shifted = value >> shift;
// ...
if (shifted && shifted != UINT64_MAX)
{
unsigned off = (unsigned)__builtin_ctzll(~shifted);
unsigned size = (unsigned)__builtin_ctzll(shifted);
shift += off + size;
}
if (size != 0) { /* zero size means skip to the next value */
s.block_off = (uint32_t)(base_offset + (shift - size));
s.size_idx = (uint32_t)(size);
memblock_rebuild_state(m->heap, &s);
if ((ret = cb(&s, arg)) != 0) return ret;
}
} while (shift != RUN_BITS_PER_VALUE);
以这个程序举例,在前面计算出的trailing_bits是61,最后3bits不可用。
然后走到这里,算出的shifted是16140901064495857664,将其转换成二进制如下:
1110000000000000000000000000000000000000000000000000000000000000
对这个数用gcc内联函数__builtin_ctzll计算出的off和size的值如下,最终得到这个块要插入的列表就是blocks[60]:
off = 0
size = 61 # 就是trailing_bits
在附加完buffer数组之后,还需要修改bucket中的元数据,让线程意识到这个桶是可用的。
/*
* bucket_attach_run - 将run附加到桶中,使其变成活跃状态
*/
int
bucket_attach_run(struct bucket *b, const struct memory_block *m)
{
os_mutex_t *lock = m->m_ops->get_lock(m);
util_mutex_lock(lock);
/*
* 对run内存块进行处理,将其附加到分配类指定的桶中
* 就是前面讲过的run_iterate_free()
*/
int ret = m->m_ops->iterate_free(m, bucket_memblock_insert_block, b);
util_mutex_unlock(lock);
if (ret == 0) {
// 让这个桶变成活跃状态
b->active_memory_block->m = *m;
b->active_memory_block->bucket = b->locked;
b->is_active = 1;
util_fetch_and_add64(&b->active_memory_block->nresv, 1);
} else {
// 附加失败,删除seglists中的所有元素
b->c_ops->rm_all(b->container);
}
return 0;
}
最后还需要原子操作将现在可用run内存大小添加到堆中的transient做一个统计信息 。
/*
* heap_run_create -- (internal) initializes a new run on an existing free chunk
*/
static int
heap_run_create(struct palloc_heap *heap, struct bucket *b,
struct memory_block *m)
{
struct alloc_class *aclass = bucket_alloc_class(b);
// 5、创建新的memory_block_run
*m = memblock_run_init(heap, m->chunk_id, m->zone_id, &aclass->rdsc);
// 6、将memory_block_run附加到分配类指定的桶中
bucket_attach_run(b, m);
//STATS_INC(heap->stats, transient, heap_run_active,
// m->size_idx * CHUNKSIZE);
if ((heap->stats)->enabled == POBJ_STATS_ENABLED_TRANSIENT ||
(heap->stats)->enabled == POBJ_STATS_ENABLED_BOTH)
util_fetch_and_add64(&(heap->stats)->transient->heap_run_active,
m->size_idx * CHUNKSIZE);
return 0;
}
7、再次从分配类指定的桶中获取内存块
前面在第二步的时候我们已经尝试过从分配类指定的桶中获取内存块了,但当时由于是分配的内存池中的第一个对象,因此桶都没有被填充。现在已经在上一步填充好了,就再尝试一次从桶中获取内存块。现在尝试的是非默认桶,桶中的容器是分段列表,获取内存块的方法在前面已经有过介绍,就是 container_seglists_get_rm_block_bestfit 这个函数。
以本文的示例程序为例,到这里刚开始桶中的布局是这个样子:
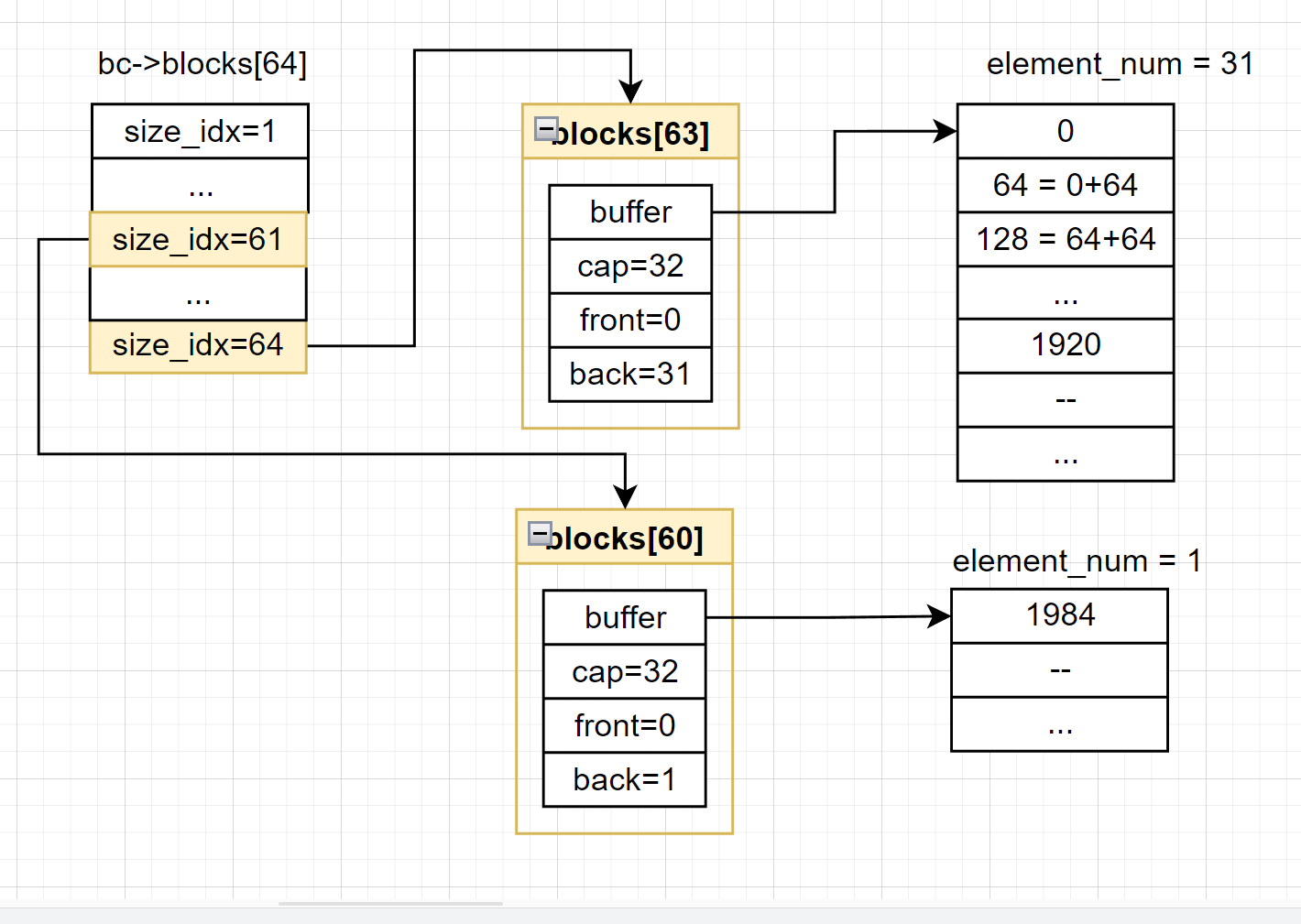
在获取完合适的内存块之后,blocks[60]中就没有元素了,这个时候还需要更新一下non-emptylist,将相应的位设置成0。
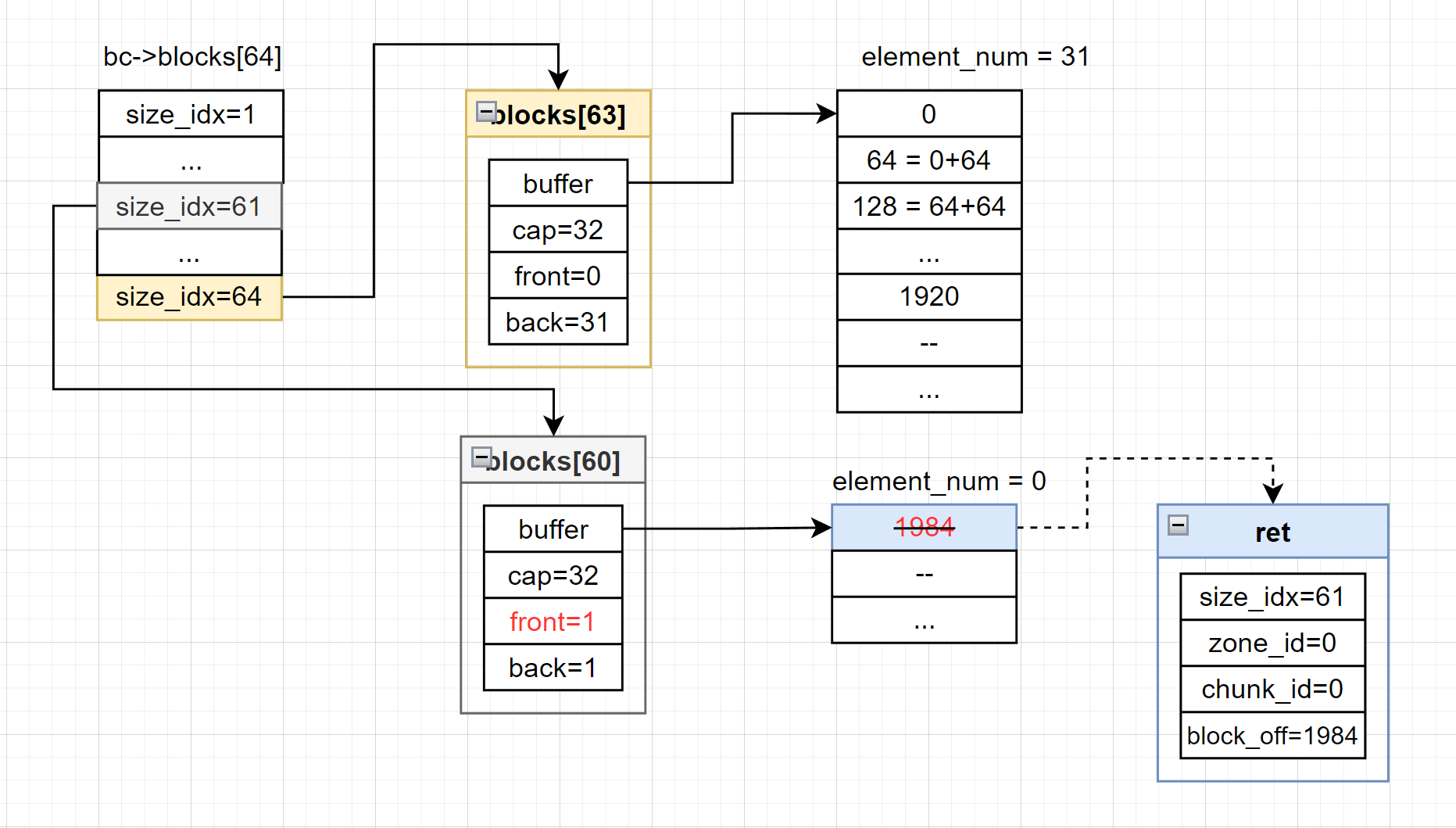
前面在介绍位图的时候已经提起过,位图中的成员变量nbits表示的是内存块中有多少个block,而每个block的大小就是对应分配类中的成员变量unit_size。
本文档中的示例程序需要分配的root对象所需要的内存只有40Bytes,只需要一个block(128Bytes)就够了。因此在获取到这个内存块之后,我们只需要将这个内存块分割出我们分配对象需要的内存大小,剩余的部分返还到桶中。
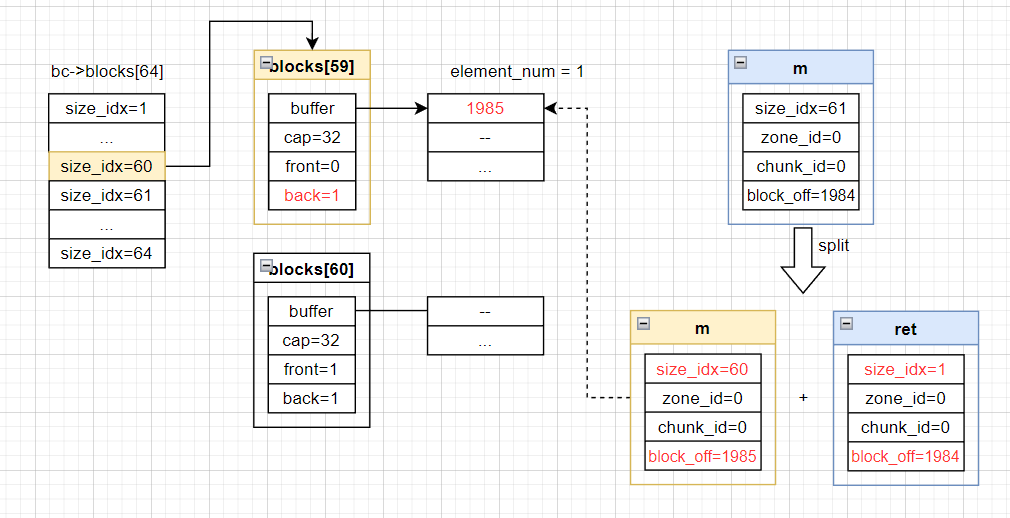
接下来要将这个切割下来的内存块保存到一个用于表示持久化内存操作动作的结构体struct pobj_action_internal,来看一下这个结构体的定义:
struct pobj_action_internal {
/* 表示操作的类型,可以是分配、释放或设置操作 */
enum pobj_action_type type;
/* 未使用的填充字段,用于对齐 */
uint32_t padding;
/* 操作特定的锁,在执行操作期间需要获取该锁 */
os_mutex_t *lock;
/* 操作特定的数据 */
union {
/* valid only when type == POBJ_ACTION_TYPE_HEAP */
struct {
uint64_t offset; // 内存块的偏移量
uint64_t usable_size; // 内存块的可用大小
enum memblock_state new_state; // 内存块的新状态
struct memory_block m; // 内存块定位信息
struct memory_block_reserved *mresv;
};
/* valid only when type == POBJ_ACTION_TYPE_MEM */
struct {
uint64_t *ptr;
uint64_t value;
};
/* padding, not used */
uint64_t data2[14];
};
};
内存池中分配多个对象
一个内存池中最多只会有一个root对象,root对象在初始化好之后会将它相对于内存池起始位置的偏移量保存到内存池中,后面就算重新打开内存池也可以根据内存池描述符pop来重新找到根对象:
/*
* pmemobj_root_construct -- returns root object
*/
PMEMoid
pmemobj_root_construct(PMEMobjpool *pop, size_t size,
pmemobj_constr constructor, void *arg)
{
// ...
root.pool_uuid_lo = pop->uuid_lo;
root.off = pop->root_offset;
// ..,
}
内存池还可以存在任意多个其他的非根对象,但是非根对象不会在内存池描述符中保存它的信息,只能通过根对象来找到,用户可以根据需求来将对象组织成任何形式,就像平常编写数据结构一样:
struct root_obj {
// ...
// 存储非根对象的持久化指针
PMEMoid other_obj;
}

分配对象的过程前面已经分析过,这里就不再赘述。
释放内存池中的对象
释放对象比较简单,第一步是根据持久化指针中的对象偏移量off来计算这个对象所在的内存块memblock的信息,下面是相关的代码:
/*
* palloc_defer_free -- creates an internal deferred free action
*/
static void
palloc_defer_free_create(struct palloc_heap *heap, uint64_t off,
struct pobj_action_internal *out)
{
out->type = POBJ_ACTION_TYPE_HEAP;
out->offset = off;
out->m = memblock_from_offset(heap, off);
heap_ensure_zone_reclaimed(heap, out->m.zone_id);
/*
* For the duration of free we may need to protect surrounding
* metadata from being modified.
*/
out->lock = out->m.m_ops->get_lock(&out->m);
out->mresv = NULL;
out->new_state = MEMBLOCK_FREE;
}
/*
* memblock_from_offset -- 从堆中起始的偏移解析内存块memblock数据
*/
struct memory_block
memblock_from_offset_opt(struct palloc_heap *heap, uint64_t off, int size)
{
struct memory_block m = MEMORY_BLOCK_NONE;
m.heap = heap;
// 计算需要释放的内存块所在的zone
off -= ((uintptr_t)&heap->layout->zone0 - (uintptr_t)heap->base);
m.zone_id = (uint32_t)(off / ZONE_MAX_SIZE);
// 计算需要释放的内存块所在的chunk
off -= (ZONE_MAX_SIZE * m.zone_id) + sizeof(struct zone);
m.chunk_id = (uint32_t)(off / CHUNKSIZE);
// 获得chunk_header
struct chunk_header *hdr = heap_get_chunk_hdr(heap, &m);
if (hdr->type == CHUNK_TYPE_RUN_DATA)
m.chunk_id -= hdr->size_idx;
off -= CHUNKSIZE * m.chunk_id;
m.header_type = memblock_header_type(&m);
off -= header_type_to_size[m.header_type];
/*
* 还记得前面讲memory_block_run的时候有说过这种内存块的大小是CHUNKSIZE的倍数
* 因此在前面减完CHUNKSIZE之后如果off为0,那么内存块的类型就是MEMORY_BLOCK_HUGE
* 否则就是 MEMORY_BLOCK_RUN
*/
m.type = off != 0 ? MEMORY_BLOCK_RUN : MEMORY_BLOCK_HUGE;
ASSERTeq(memblock_detect_type(heap, &m), m.type);
m.m_ops = &mb_ops[m.type];
uint64_t unit_size = m.m_ops->block_size(&m);
if (off != 0) { /* run */
off -= run_get_data_offset(&m); // 减去位图的大小
off -= RUN_BASE_METADATA_SIZE; // 减去chunk_run_header的大小
m.block_off = (uint16_t)(off / unit_size); // 计算block_off
off -= m.block_off * unit_size;
}
struct alloc_class_collection *acc = heap_alloc_classes(heap);
if (acc != NULL) {
struct alloc_class *ac = alloc_class_by_run(acc,
unit_size, hdr->flags, hdr->size_idx);
if (ac != NULL)
m.cached_bitmap = &ac->rdsc.bitmap;
}
m.size_idx = !size ? 0 : CALC_SIZE_IDX(unit_size,
memblock_header_ops[m.header_type].get_size(&m));
ASSERTeq(off, 0);
return m;
}
可以看到假如对应的块所在的CHUNK的类型是RUN_DATA的话,m->chunk_id 的计算方式就和其他的不太一样,假如现在由一个内存块的size_idx为4,那么数组中对应的部分的type、size_idx如下:
type - [RUN, RUN_DATA, RUN_DATA, RUN_DATA]
size_idx - [4, 1, 2, 3]
然后接下来要根据这个被释放掉的memory_block去修改对应的位图以及更新对应的回收器数据:
/*
* recycler_inc_unaccounted -- increases the number of unaccounted units in the
* recycler
*/
void
recycler_inc_unaccounted(struct recycler *r, const struct memory_block *m)
{
util_fetch_and_add64(&r->unaccounted_total, m->size_idx);
util_fetch_and_add64(&r->unaccounted_units[m->chunk_id],
m->size_idx);
}
这里就可以顺便讲一下recycler这个结构体的成员变量含义了:
struct recycler {
struct ravl *runs;
struct palloc_heap *heap;
/*
* How many unaccounted units there *might* be inside of the memory
* blocks stored in the recycler.
* The value is not meant to be accurate, but rather a rough measure on
* how often should the memory block scores be recalculated.
*
* Per-chunk unaccounted units are shared for all zones, which might
* lead to some unnecessary recalculations.
*
* 例如 unaccounted_units[13] = 5,就代表第14个chunk中有5个units被释放掉了
*/
size_t unaccounted_units[MAX_CHUNK];
/*
* 记录了回收器对应的桶中释放掉了多少个unit
*/
size_t unaccounted_total;
size_t nallocs;
size_t *peak_arenas;
VEC(, struct recycler_element) recalc;
os_mutex_t lock;
};
触发回收器recycler的条件
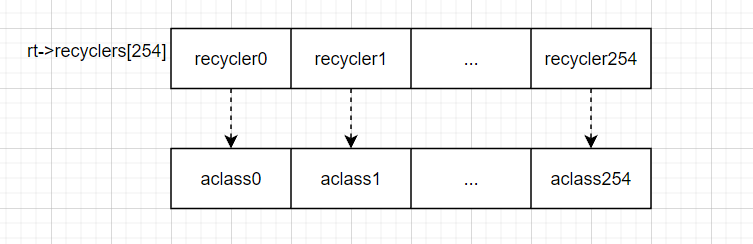
前面其实还有一个结构体没有介绍过,那就是分配类recycler。
假设现在有一个memory_block_run内存块,原本run中的内存已经被使用完了,也就是run中的bitmap记录的units状态全部是已使用。
然后其中有至少一个units被释放掉了,位图中相应的部分被修改为了可用。等到再次从这个run中申请内存的时候,就会触发回收器从run中回收可用的unit。和桶一样,回收器也是和分配类一一对应的:
在回收unit之前,首先要根据位图来计算chunk_run中的空闲units的数量,以及目前能满足的最大分配请求。在计算完之后将生成的信息插入到回收器recycler的ravl-tree中,相关的代码如下:下面是相关的代码:
/*
* heap_reclaim_run -- 计算run中的空闲内存大小,并且将相关的信息插入到recycler回收器中
*/
static int
heap_reclaim_run(struct palloc_heap *heap, struct memory_block *m, int startup)
{
struct chunk_run *run = heap_get_chunk_run(heap, m);
struct chunk_header *hdr = heap_get_chunk_hdr(heap, m);
struct alloc_class *c = alloc_class_by_run(
heap->rt->alloc_classes,
run->hdr.block_size, hdr->flags, m->size_idx);
os_mutex_t *lock = m->m_ops->get_lock(m);
util_mutex_lock(lock);
struct recycler_element e = {
.free_space = 0, /* 一个run中有多少空闲字节 */
.max_free_block = 0, /* 这个run中能处理的最大请求是什么 */
.chunk_id = m->chunk_id,
.zone_id = m->zone_id,
};
m->m_ops->calc_free(m, &e.free_space, &e.max_free_block);
util_mutex_unlock(lock);
if (e.free_space == c->rdsc.nallocs)
return 1;
struct recycler *recycler = heap_get_recycler(heap, c->id,
c->rdsc.nallocs);
if (recycler != NULL) {
util_mutex_lock(&recycler->lock);
ret = ravl_emplace(recycler->runs, &e);
util_mutex_unlock(&recycler->lock);
}
return 0;
}
/*
* run_calc_free -- 计算chunk_run中有多少个空闲的units
*/
static void
run_calc_free(const struct memory_block *m,
uint32_t *free_space, uint32_t *max_free_block)
{
struct run_bitmap b;
run_get_bitmap(m, &b);
for (unsigned i = 0; i < b.nvalues; ++i) {
uint64_t value = ~b.values[i];
/*
* value为0表示b.values[i]=0b111111...111
* 表示chunk_run位图中对应的那部分内存全部已经被使用过了
* 反之表示位图中对应的那部分有可用的内存存在,就需要计算空闲内存的大小
*/
if (value == 0)
continue;
// 计算value二进制位中1的数量
uint32_t free_in_value = util_popcount64(value);
// 计算这个run内存块中总共的空闲内存大小
*free_space = *free_space + free_in_value;
/*
* If this value has less free blocks than already found max,
* there's no point in calculating.
*/
if (free_in_value < *max_free_block)
continue;
/* if the entire value is empty, no point in calculating */
if (free_in_value == RUN_BITS_PER_VALUE) {
*max_free_block = RUN_BITS_PER_VALUE;
continue;
}
/* if already at max, no point in calculating */
if (*max_free_block == RUN_BITS_PER_VALUE)
continue;
/*
* Calculate the biggest free block in the bitmap.
* This algorithm is not the most clever imaginable, but it's
* easy to implement and fast enough.
*/
uint16_t n = 0;
while (value != 0) {
value &= (value << 1ULL);
n++;
}
if (n > *max_free_block)
*max_free_block = n;
}
}
在确认好chunk_run中确实有空闲的unit之后,下一步就是要将chunk_run中的空闲unit插入到桶bucket中,这个在前面有分析过,其实就是按照chunk_run中的位图, 找到其中连续的内存块,然后将内存块插入到bucket_container_seglists中。
在将chunk_run中空闲的块全部填充到桶内之后,后面分配内存的步骤就和前面分配root对象一样了。