libpmemobj内存分配器设计
持久内存开发工具包(Persistent Memory Development Kit, PMDK)是一组库和工具。在Linux操作系统上进行了调整和验证,这些库基于基于DAX(Direct Access)功能,允许应用程序将持久内存作为内存映射文件(memory-mapped files)进行访问。
由于PMDK提供了大量的库,因此必须仔细考虑自身选择。PMDK提供了易失性库和持久化性库两种类型的库。其中持久性库可以帮助应用程序在出现故障时保证数据结构的一致性,能够充分地来利用持久内存的独特性。
持久性库中有一个提供事务对象存储的C库:libpmemobj,它可以为持久内存变成提供动态内存分配器以及其他常规功能。如果需要在数据结构设计方面具有灵活性,但可以使用通用内存分配器和事务时,可以使用这个库。
在libpmemobj这个库中,引入了内存池的概念。库中通过mmap(flags:MAP_SYNC)系统调用,将内存池文件保存到挂载DAX的文件系统中。
PMDK内存分配器设计
内存池将持久内存空间划分为多个可分配的内存块,这些内存块通过libpmemobj中的内存分配器的分配策略进行管理。通过内存池的管理,应用程序可以更高效地使用持久内存,并且能够在内存的分配和回收过程中保证数据的持久性。
内存池布局
内存池分为了三个部分:内存池描述符、用于保存事务操作的通道、用于对象内存分配的堆。
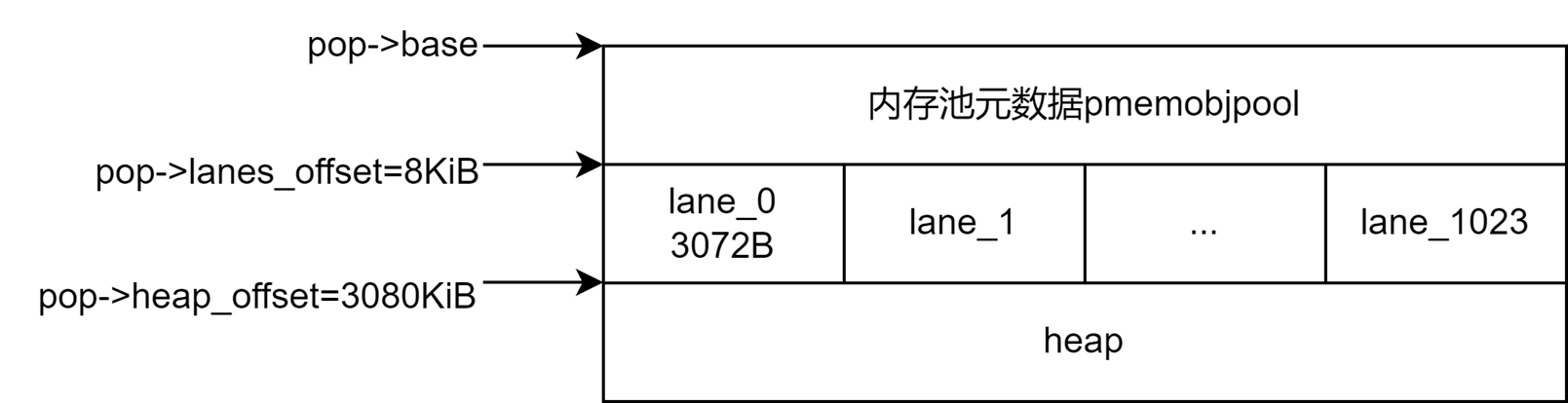
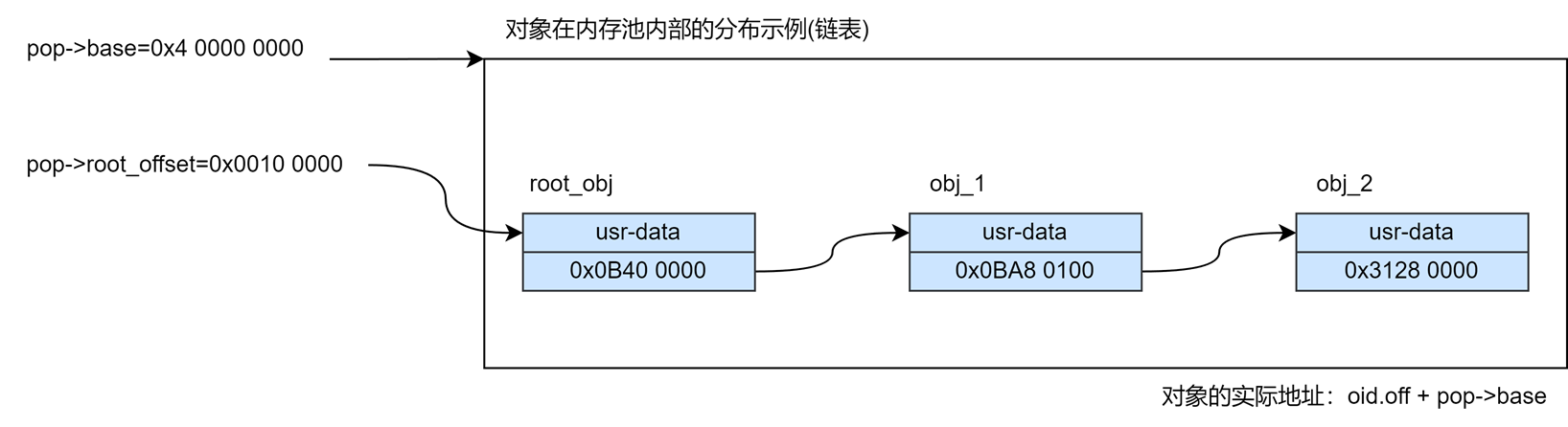
内存池描述符保存在内存池的开始位置,用于保存内存池中的元数据,例如内存池内通道的数量、堆的大小以及偏移量、根对象的大小以及偏移量等。libpmemobj将数据放在“对象”中,每个对象都会有一个唯一的持久化指针PMEMoid来描述,指针中会有一个对象相对于池基地址的偏移量。
typedef struct pmemoid {
uint64_t pool_uuid_lo; // 每一个pool都有一个uuid唯一标识自己
uint64_t off; // 对象在该pool中的偏移量
} PMEMoid;
对象有根对象和非根对象两种类型,其中一个内存池中只会有一个根对象,根对象的信息保存在内存池描述符中。但是内存池描述符中不会保存非根对象的信息,假如有多个对象,则必须要在根对象中包含至少一个对象的持久化指针信息。用户可以根据需求将内存池中的对象组织成任何形式,例如链表、b+树等。
通道是PMDK中的事务缓冲区,用于保存正在运行的事务与其持久日志之间的关联。通道的数量有限、大小固定。堆是在内存池中实际存放用户数据的地方,内存分配器就是在堆中申请内存块。堆中的可用内存被划分成大小相同的区域,最后一个区域除外,它可能会比其他的区域小。在内存池初始化的阶段,每个区域会被进一步分为多个大小相等(256Kib)的CHUNK;在申请对象的阶段,被选中的CHUNK还会被细分为大小相等的unit。
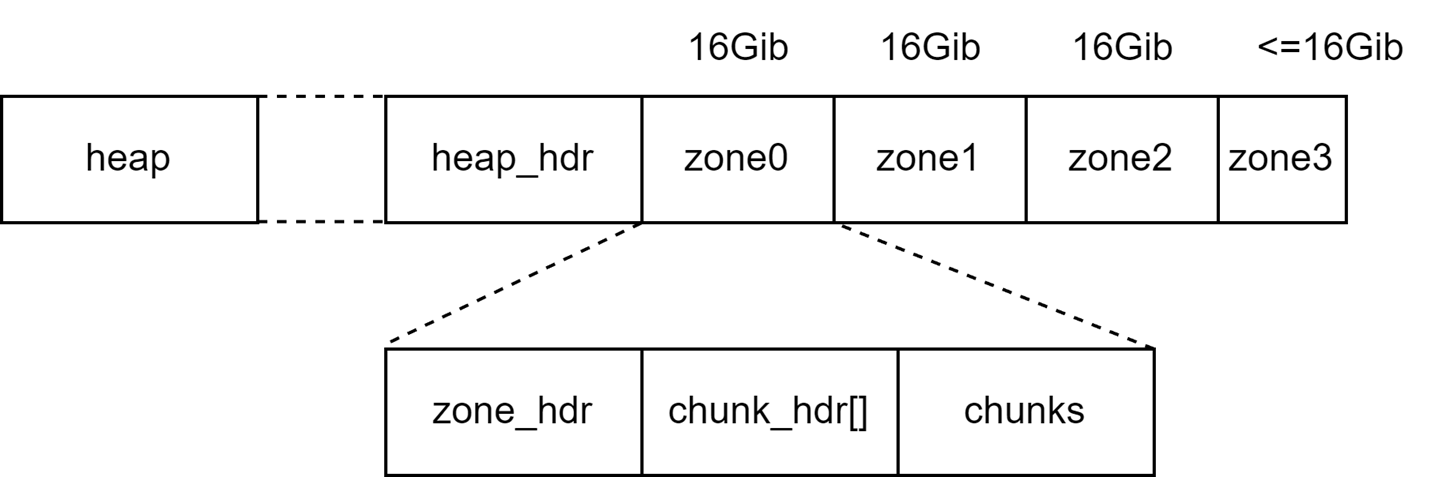
在文章后面的部分,CHUNK表示堆中大小为256Kib的块;多个连续的CHUNK表示为小写chunk;被选中用于进行内存分配的连续CHUNK表示为run。
每个区域的开始处都会有一个chunk_headers数组,通过这个数组可以判断区域内部的布局。
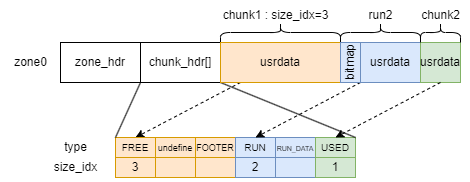
分配器内的组件
在首次分配特定的对象时,线程会从堆中选中一个或多个连续的CHUNK,然后将其分割成多个unit,因此unit的大小决定了在内存块中产生的内存碎片大小。为了保证内存碎片的最小化,libpmemobj中提供了一个分配类数组aclasses,数组中有255个分配类,每个分配类都有特定的unit_size,能够在特定的run大小中保证内存碎片的最小化。例如,假设当用户需要分配大小为1472Bytes的对象时,就会选中aclass9作为分配类,然后选中 size_idx=2 个连续的CHUNK转化成分配对象用的run,以 unit_size = 1472Bytes 为粒度,将整个run分割成多个units,然后返回一个unit给用户使用。
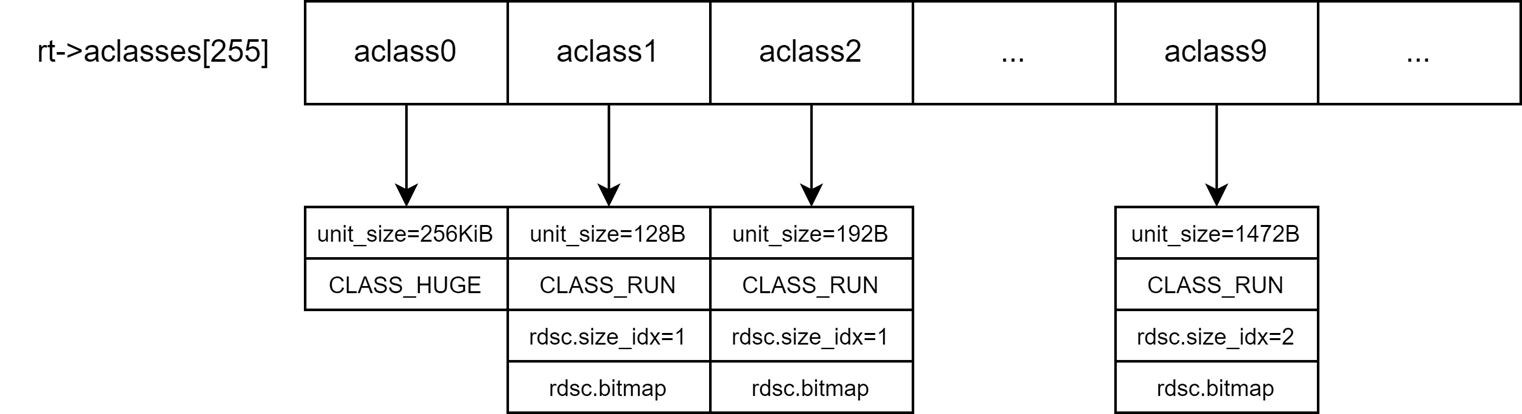
在run的起始处会有一个位图去记录run中每个unit的状态,0代表unit可用,1代表unit已被使用。只有在对象分配释放的最后阶段,线程会在通道中添加一个操作日志,然后修改对象对应在位图中的状态。

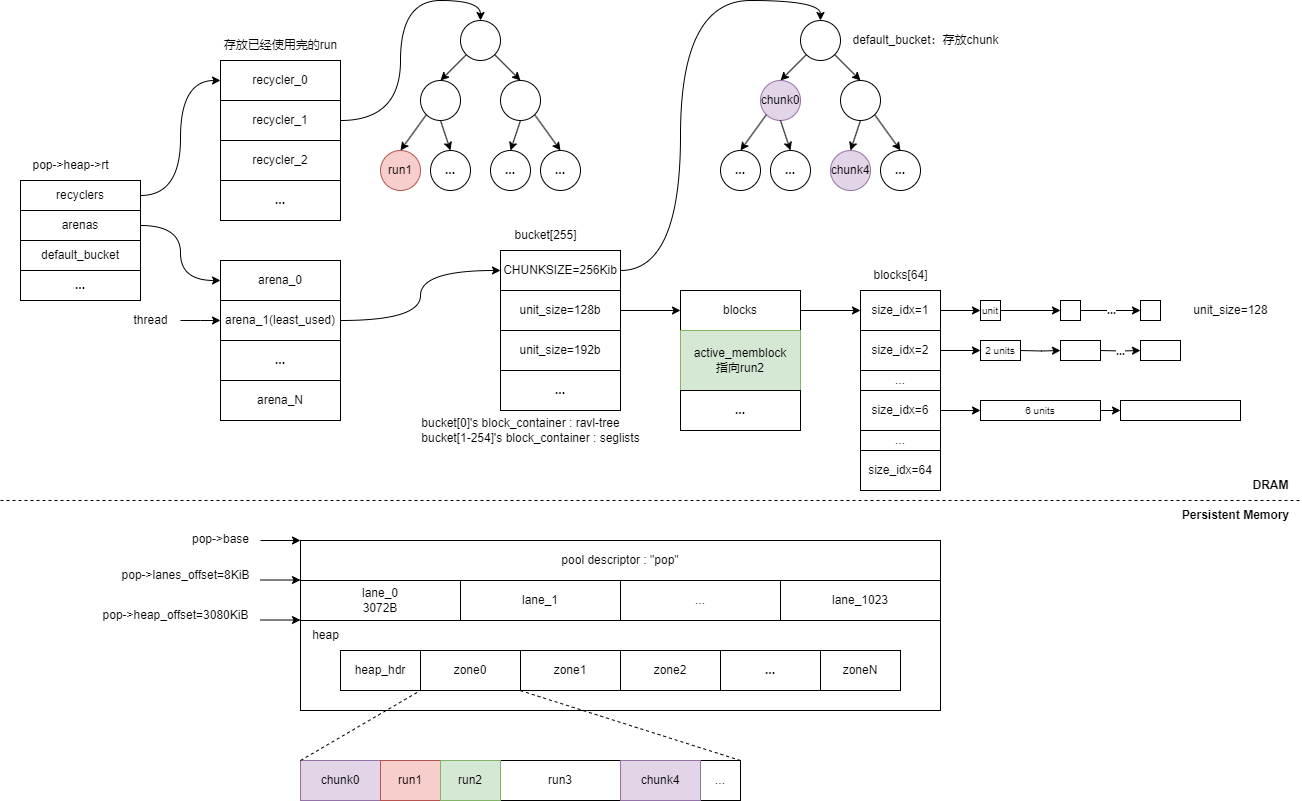
为了减少线程间进行资源的竞争,PMDK中沿用了ptmalloc2中的解决方案,引入了arena这个概念。内存池中的arena数量跟系统中处理器核心个数一致。每个试图从池中申请内存的线程都会基于LRU算法绑定一个最少使用的arena在其中进行内存管理。
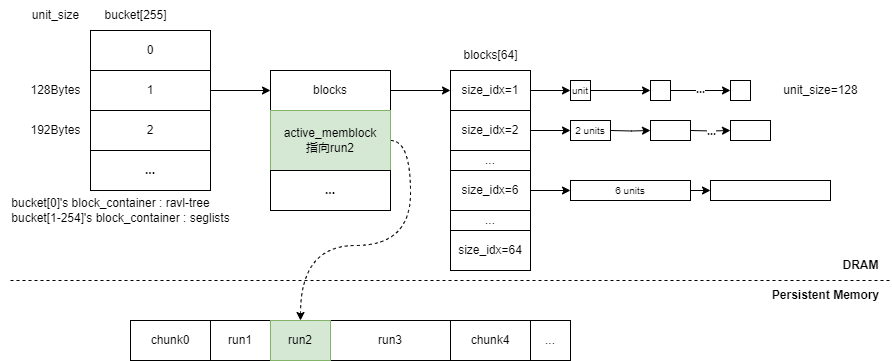
每个arena都会有个指针数组,数组中的每个元素都会指向一个桶,一共有255个桶指针,对于第[2-255]个桶(非默认桶),在确定好使用的分配类之后,会根据分配类在数组中的下标去选中对应的桶,然后从第一个桶(默认桶)中取出chunk作为分配unit所用的run,并将这个run与前面找到的非默认桶进行绑定。
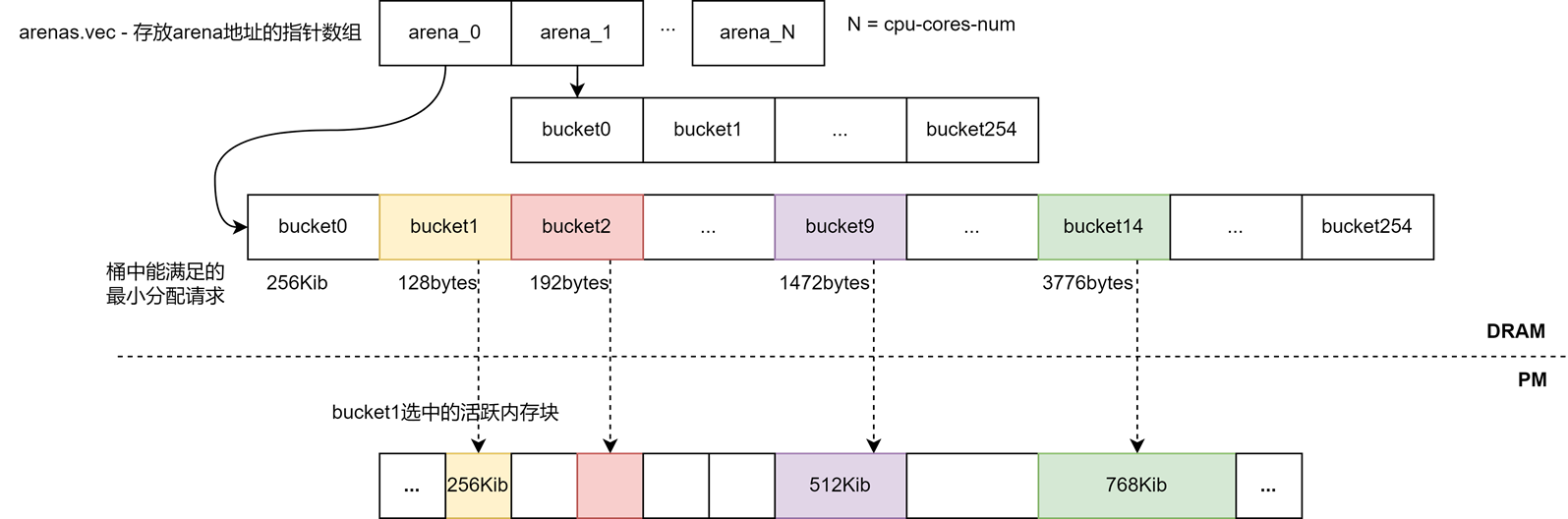
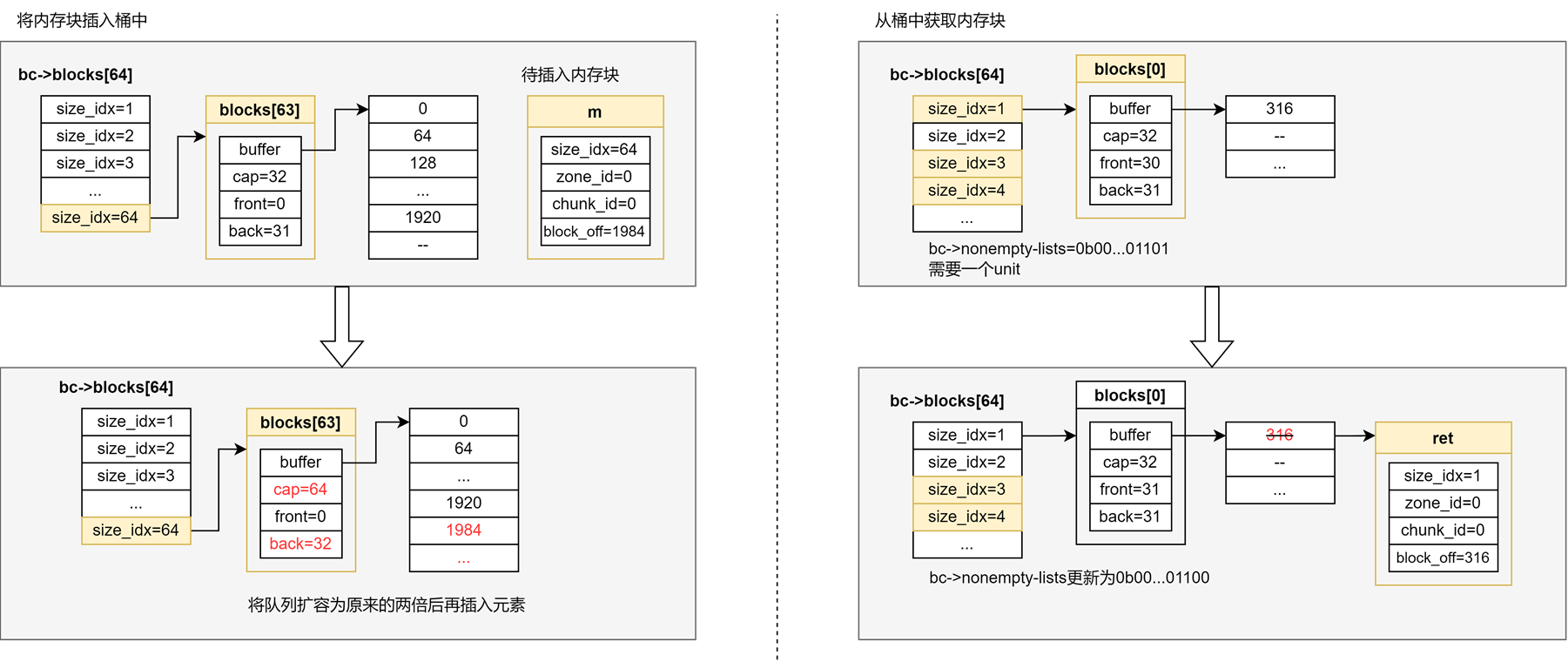
类似于Linux内存管理中的伙伴系统,非默认桶中会用分离列表(segregated lists)的方式组织起run中空闲unit的索引信息。它将内存块根据连续unit数量来分组,每个组使用一个独立的队列来管理同一尺寸的内存块,队列内节点存储的数据是unit对应在run中的偏移量,也就是它属于run中的第几个unit。附加新的run到桶中时,填充内存块是按照64个unit一组,填充到桶的最后一个队列blocks[63]中。假如run中最后剩下x<64个unit,就将最后一个内存块填充到blocks[x]中。
对于默认桶,它是整个内存池中只有一个的,所有arena的bucket[0]指针都会指向它。它用RAVL树(一种删除无需进行自平衡的变种AVL树)组织起内存池中连续的CHUNK内存块。有两种情况会触发它:
- 假如待分配的对象大小大于2560Kib(10个CHUNK),就会直接从默认桶中分配chunk。
- 对于小于2560Kib的对象,由于在PMDK中,释放内存的API内部实现只会更新run中的位图,但并不会更新桶以及回收器中的数据,因此当从非默认桶中分配内存时发现剩余的可用unit无法满足用户的分配需求,最优先会尝试通过定位到run中的位图来更新桶中数据,假如还是不行,就将这个run中相关的信息插入到回收器,然后尝试后续处理去填充这个桶,其中有一个方案就是从默认桶中分配新的chunk与非默认桶进行绑定。
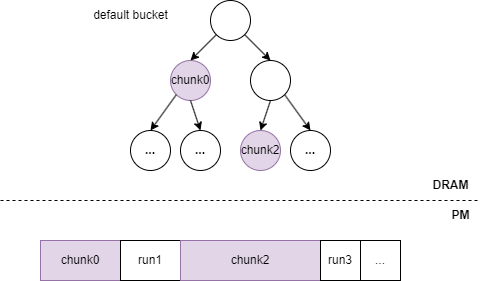
默认桶中的RAVL树中进行平衡的指标有三个:chunk的大小(这个chunk是由多少连续的CHUNK组成的)、chunk所属的区域、以及chunk在区域中的下标(这个chunk前面有多少个CHUNKSIZE大小的块),指标的权重由高到低,默认桶中的RAVL树通过这三个指标自定义compare方法来进行树的自平衡,并且通过自定义谓词从树中查找符合要求的节点。
enum ravl_predicate {
RAVL_PREDICATE_EQUAL = 1 << 0,
RAVL_PREDICATE_GREATER = 1 << 1,
RAVL_PREDICATE_LESS = 1 << 2,
RAVL_PREDICATE_LESS_EQUAL =
RAVL_PREDICATE_EQUAL | RAVL_PREDICATE_LESS,
RAVL_PREDICATE_GREATER_EQUAL =
RAVL_PREDICATE_EQUAL | RAVL_PREDICATE_GREATER,
};
前面提到当从非默认桶中分配内存时发现剩余的可用unit无法满足用户的分配需求,就会触发回收器。在内存分配器中,回收器用来保存被使用完的run的相关信息,内部的组织方式同样是RAVL树,树中每个节点保存了一个被使用完的run的信息,其中包括了run中的空闲unit数量free_space、可以满足的最大分配请求max_free_block、以及在内存池中定位到run的信息。
回收器的树中进行自平衡的指标和默认桶有所区别,其中的RAVL树中进行平衡的指标有四个:max_free_block、free_space、run所属的区域、以及run在区域中的下标(这个run前面有多少个CHUNKSIZE大小的块),指标的权重由高到低,回收器中的RAVL树通过这四个指标自定义compare方法来进行树的自平衡。
内存池中有255个回收器被组织到一个数组中。对于第x个回收器中保存的run,其中的unit_size都是aclasses[x].unit_size。
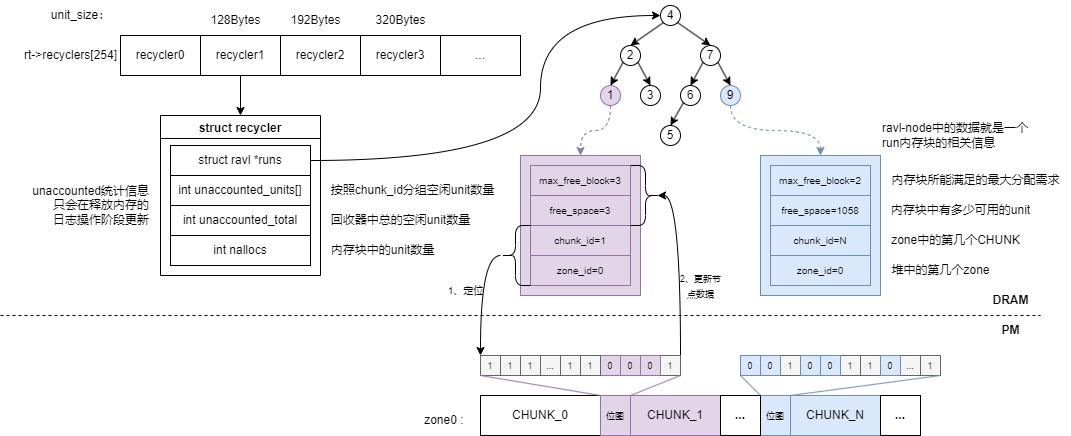
总体来说,内存分配器的重要组件包括了分配类、桶、以及回收器,下面是内存分配器的总体架构图
分配对象API内部实现
下面是分配对象的总体流程图:
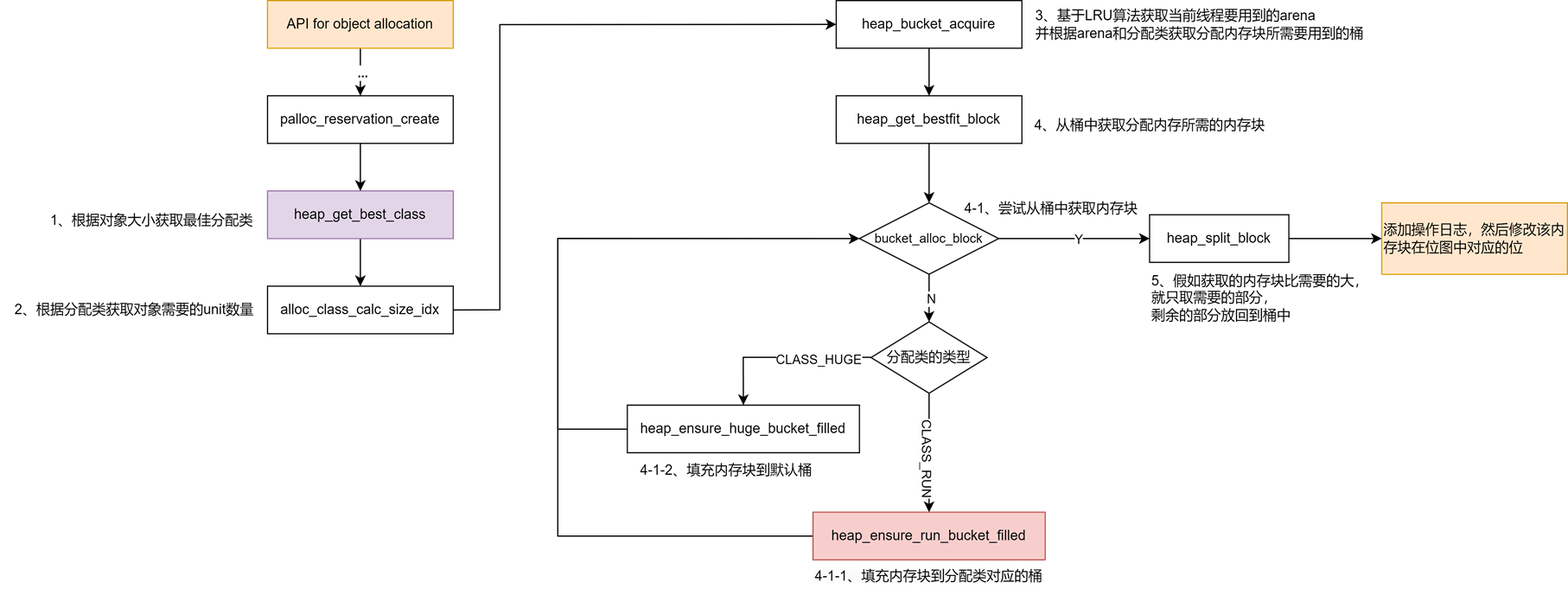
在分配对象的开始,会根据带分配对象的大小获取到最佳的分配类,以确定好run的大小以及保证run中的内存碎片最小化。
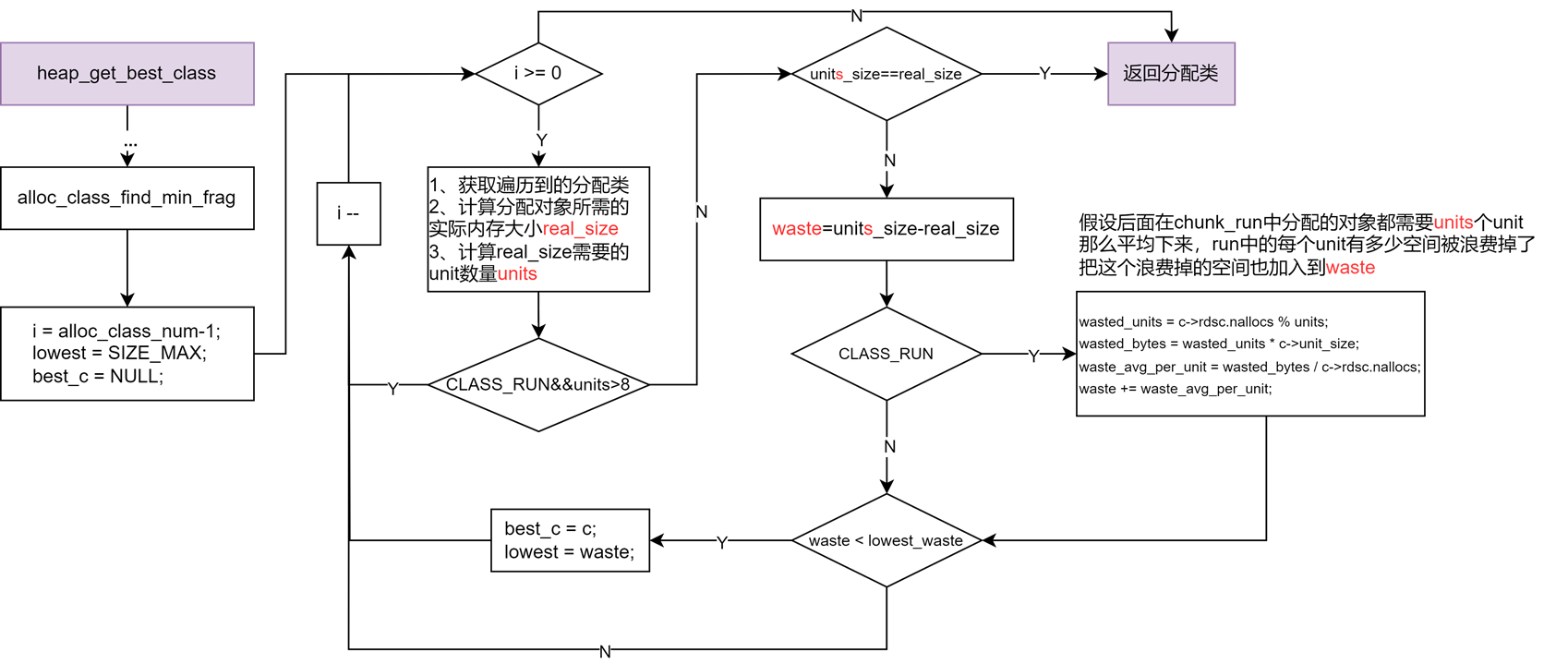
从非默认桶中分配内存
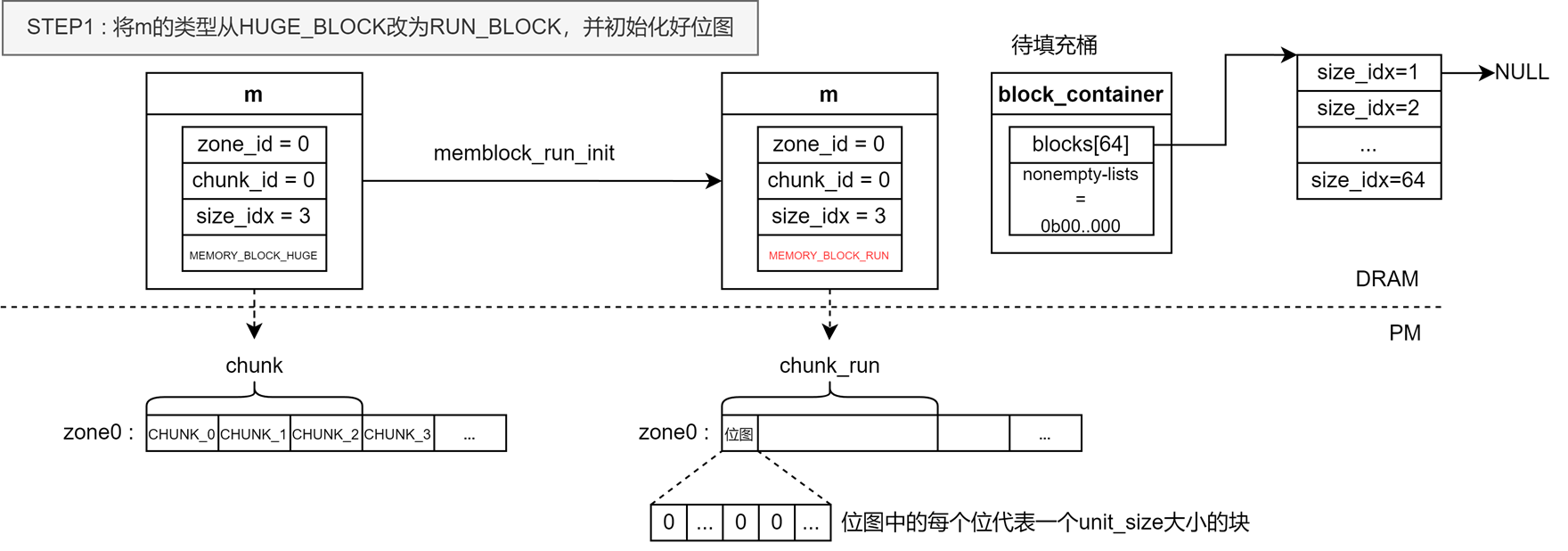
假如对象的大小小于2560Kib,接下来需要根据分配类来获取到对象需要的unit数量,然后查看当前申请内存的线程是否有绑定的arena,假如没有,就基于LRU算法获取当前线程要用到的arena并与其绑定,然后根据arena以及分配类获取到分配对象所要用到的桶,然后从桶中获取分配内存所需的内存块,下面这张图展示了如何从桶中取出/插入内存块:
假如发现桶中剩余的可用unit无法满足用户的分配需求,最优先会将run从桶中移除后,尝试通过定位到与桶绑定的run中的位图来更新桶中数据,更新后会有两种情况:
- run中所有unit都是空闲状态,将run转换成chunk,并查看它在内存池中的左右邻居是不是chunk,假如是就将它们合并,最后将更新后的chunk索引插入到默认桶中
- run中还有unit正在被使用,将run的相关信息插入到回收器中。
接下来会尝试在特定unit_size的回收器中查找RAVL树中的记录是否有能够满足用户分配需求的run,假如有就将其从回收器中移除并附加到桶中。
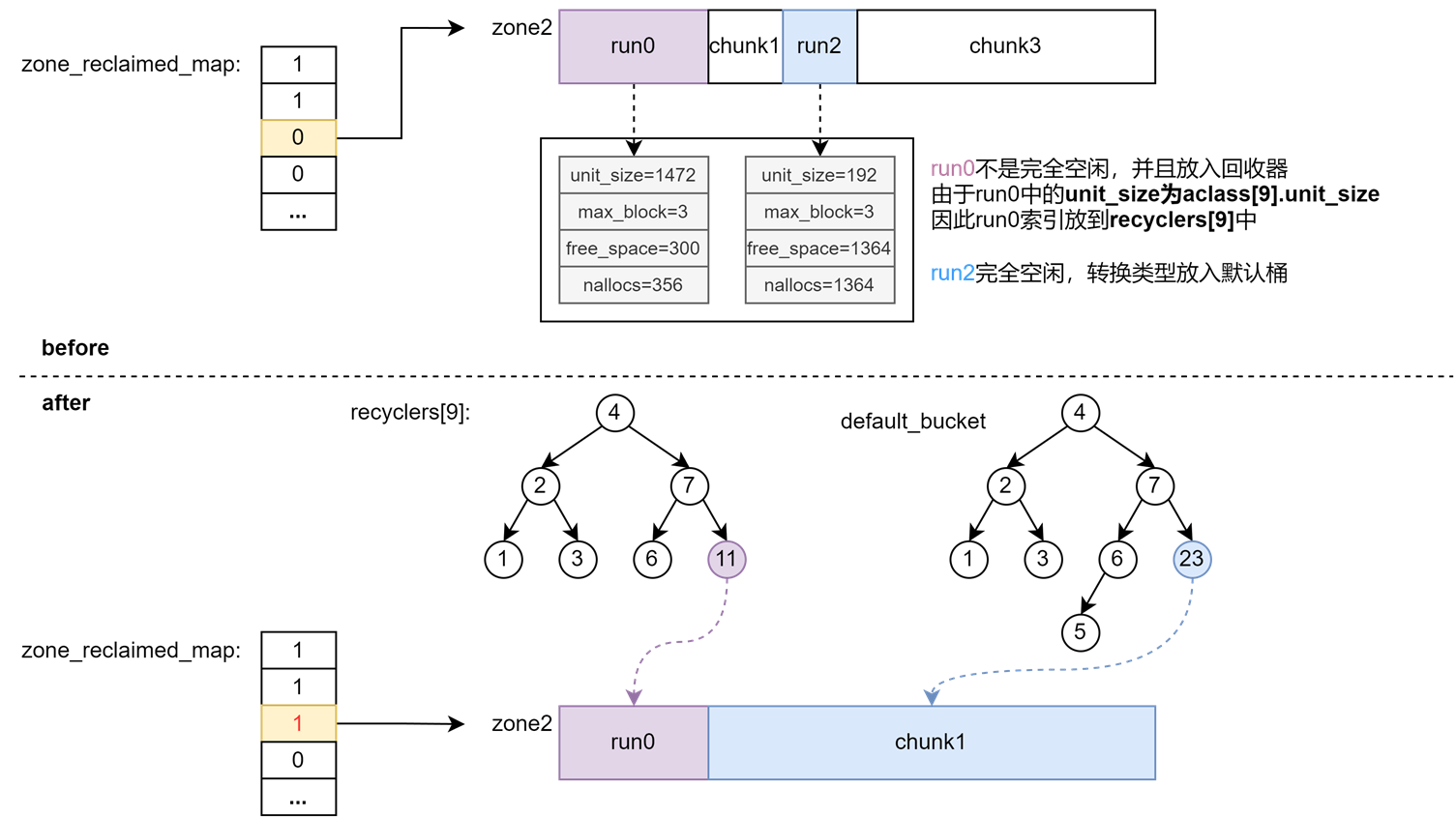
如果尝试从回收器中索引可用内存块失败了,接下来会找到当前内存池中首个收回的区域reclaimed_zone,然后根据区域起始处的chunk_headers数组遍历区域内的chunk或run进行处理:
- 假如是run,计算run中空闲unit数量以及能满足的最大分配请求。假如发现run中的unit全部空闲,则将其转换成chunk并合并邻居后插入默认桶中;否则将其插入回收器。
- 假如是chunk,则合并邻居后插入到默认桶中。
收回的区域(reclaimed_zone)目前只发现了两种情况,要么是这个区域之前没有被使用过,要么是进程正常/异常重启后,所有的区域都会变成收回的区域。
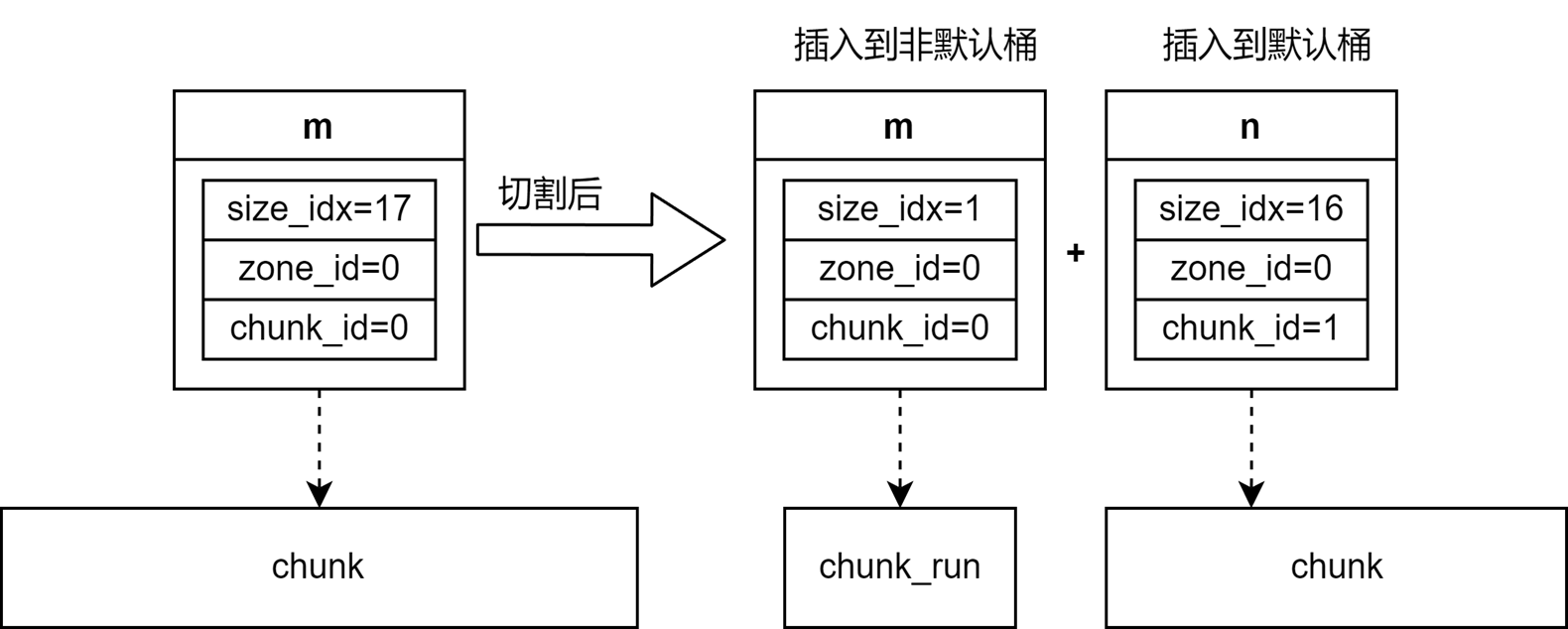
在处理完reclaimed_zone之后,会再次尝试从回收器中寻找能满足分配请求的节点。假如有就将其附加到桶中。假如还是没有,那么就会尝试从默认桶中获取chunk,假如找到的chunk比所需的run要大,那么就会将chunk切割成两部分,一部分当作run附加到桶中,一部分重新插回到默认桶。
如果发现默认桶中没有记录的chunk了,那么就会向默认桶中填充内存块。
- STEP-1:首先会遍历遍历内存池中的每个回收器,在选中的回收器中会遍历RAVL树的所有元素,记录下回收器中所有完全空闲的内存块,然后将这些块初始化成chunk,并尝试将其与邻居合并,然后将合并块插入到默认桶中。
- STEP-2:假如STEP-1中一个完全空闲的内存块都没有发现,就会去下一个reclaimed_zone遍历处理区域内的chunk或run。假如是run,计算run中空闲unit数量以及能满足的最大分配请求。假如发现run中的unit全部空闲,则将其转换成chunk并合并邻居后插入默认桶中;否则将其插入回收器。假如是chunk,则合并邻居后插入到默认桶中。
- STEP-3:假如前面两步都失败了,就会尝试直接扩展堆大小,在刚开始初始化内存池中的堆的时候,内存池中预留了一部分内存用于进行堆扩展。
在附加run到桶中之后,还要对run进行处理,将run中的unit信息记录到桶中。
从默认桶中分配内存
假如发现对象的大小大于2560Kib(10个CHUNK大小),就会直接在默认桶中分配仅能满足申请一个对象的free_chunk,如果发现默认桶中的free_chunk无法满足用户分配请求了,那么就会向默认桶中填充内存块。
- STEP-1:首先会遍历遍历内存池中的每个回收器,在选中的回收器中会遍历RAVL树的所有元素,记录下回收器中所有完全空闲的内存块,然后将这些块初始化成chunk,并尝试将其与邻居合并,然后将合并块插入到默认桶中。
- STEP-2:假如STEP-1中一个完全空闲的内存块都没有发现,就会去下一个reclaimed_zone遍历处理区域内的chunk或run。假如是run,计算run中空闲unit数量以及能满足的最大分配请求。假如发现run中的unit全部空闲,则将其转换成chunk并合并邻居后插入默认桶中;否则将其插入回收器。假如是chunk,则合并邻居后插入到默认桶中。
- STEP-3:假如前面两步都失败了,就会尝试直接扩展堆大小,在刚开始初始化内存池中的堆的时候,内存池中预留了一部分内存用于进行堆扩展。
释放对象API内部实现
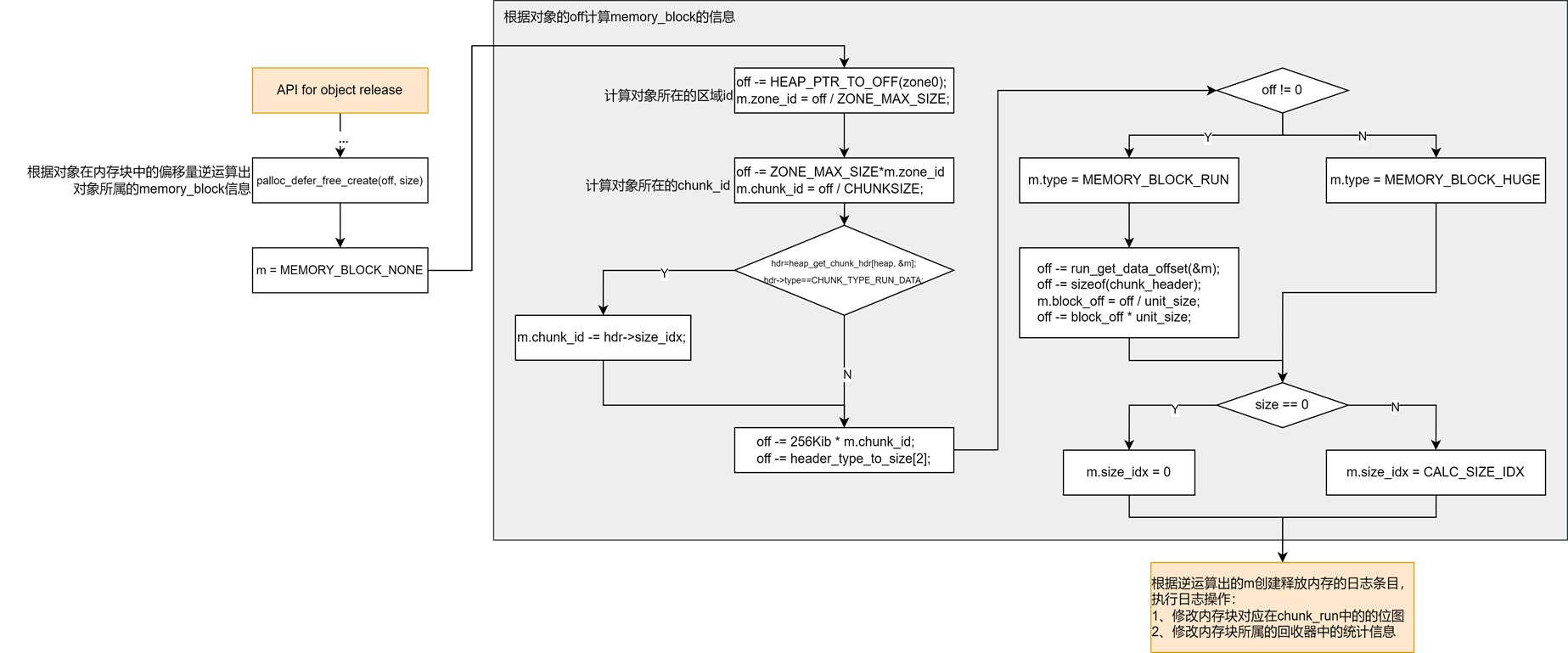
释放对象比较简单,第一步是根据持久化指针中的对象偏移量off来计算这个对象所在的内存块memblock的信息,然后执行日志操作去修改相关信息:
- 对象所在的内存块属于run,会修改内存块对应在run中的位图以及内存块所属回收器中的统计信息,这个统计信息是指回收器中总的空闲unit数量以及run所拥有的CHUNK中空闲unit的数量。
- 对象所在的内存块属于used_chunk,会修改其在zone中对chunk_headers数组对应的元素