x86汇编指南
本文介绍32位x86汇编语言编程的基础知识,涵盖了一小部分可用指令和汇编指令。有几种不同的汇编语言可以生成x86机器代码。在CS216中我们将使用微软宏汇编器(MASM)作为汇编器。MASM使用标准的英特尔语法来书写x86汇编代码。
完整的x86指令集非常庞大且复杂(英特尔的x86指令集手册超过2900页),我们无法在本指南中全部涵盖。例如,存在一个16位子集合的x86指令集。使用16位程序模型可能会相当复杂。它具有分段内存模型、对寄存器使用更多限制等等。在本指南中,我们将把注意力限制在更现代化的x86编程方面,并只深入到足够详细以获得对于x86编程基础感觉所需的指令集。
寄存器
现代(即386及以上)的x86处理器有八个32位通用寄存器,如图1所示。这些寄存器的名称大多是历史遗留下来的。例如,EAX曾被称为累加器,因为它被许多算术操作使用;ECX则被称为计数器,因为它用于保存循环索引。虽然在现代指令集中大部分寄存器已经失去了特殊用途,但按照惯例,其中两个保留给特殊目的——堆栈指针(ESP)和基址指针(EBP)。
对于EAX、EBX、ECX和EDX寄存器,可以使用子段。例如,EAX的最低有效2字节可以视为一个名为AX的16位寄存器。AX的最低有效字节可作为一个名为AL的8位单一寄存器使用;而AX的最高有效字节可作为一个名为AH的8位单一寄存器使用。这些名称都指向同一个物理寄存器。当将两个字节大小数据放入DX时,则会影响到DH、DL和EDX三者之间值得更新。这些子寄存器主要是从旧版16位指令集中继承下来,并且在处理小于32位数据(如1字节ASCII字符)时非常方便。
在汇编语言中引用寄存器时,名称不区分大小写。例如,EAX和eax这两个名称指的是同一个寄存器。
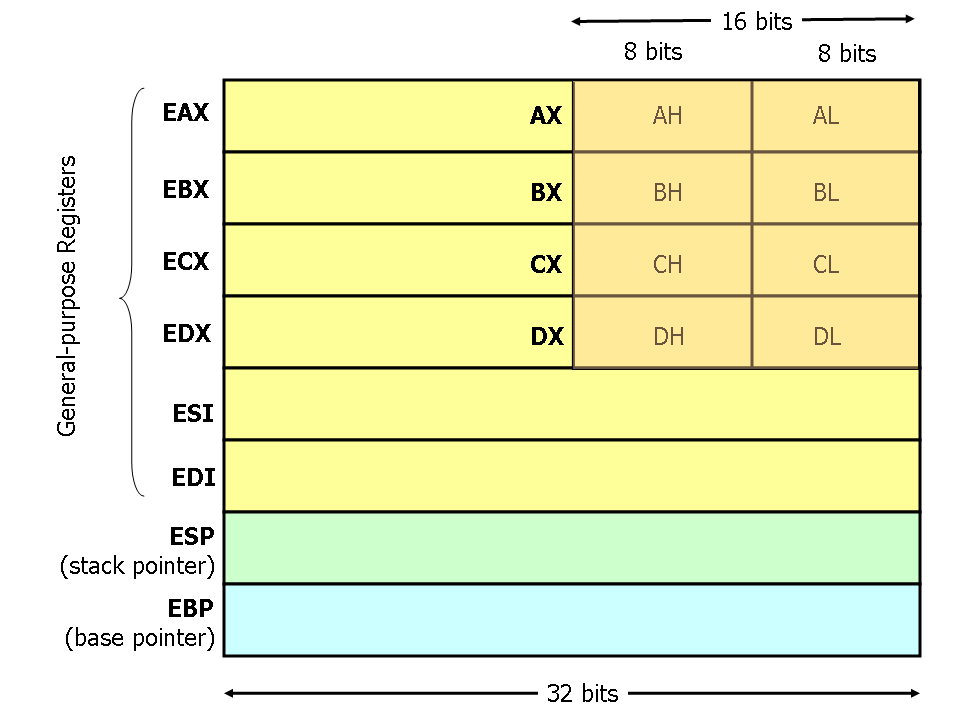
Figure 1. x86 Registers
内存和寻址模式
声明静态数据区域
您可以使用特殊的汇编指令来在x86汇编中声明静态数据区域(类似于全局变量)。数据声明应该在.DATA指令之前。在这个指令之后,可以使用DB、DW和DD指令分别声明一个字节、两个字节和四个字节的数据位置。声明的位置可以用名称标记以供以后引用 - 这类似于通过名称声明变量,但遵守一些较低级别的规则。例如,按顺序声明的位置将位于相邻内存中。
示例声明:
.DATA
var DB 64 ; 声明一个名为var的字节,其值为64。
var2 DB ? ; 声明一个未初始化的字节,名为var2。
DB 10 ; 声明一个没有标签的字节,其值为10。它所在位置是var2 + 1。
X DW ? ; 声明一个未初始化的2字节值,名为X。
Y DD 30000 ; 声明一个4字节值,名为Y,并初始化为30000。
与高级语言不同,在x86汇编语言中数组只是连续存储在内存中的多个单元格。数组可以通过列出数值来进行声明,如下面第一个示例所示。另外两种常用于声明数据数组的方法是DUP指令和字符串文字(string literals) 的使用。DUP指令告诉汇编器重复一个表达式给定次数。例如,4 DUP(2) 等同于 2, 2, 2, 2。
一些示例:
Z DD 1, 2, 3 ; 声明三个4字节值,初始化为1、2和3。位置Z + 8的值将是3。
bytes DB 10 DUP(?) ; 声明从位置bytes开始的10个未初始化字节。
arr DD 100 DUP(0) ; 声明从位置arr开始的100个4字节单元格,全部初始化为0。
str DB 'hello',0 ; 声明从地址str开始的6个字节,用ASCII字符表示hello以及空(null)字节。
内存寻址
现代的兼容x86处理器能够寻址高达232字节的内存:内存地址为32位宽。在上面的示例中,我们使用标签来引用内存区域,这些标签实际上被汇编器替换为指定内存地址的32位数量。除了支持通过标签(即常量值)引用内存区域之外,x86还提供了一种灵活的计算和引用内存地址的方案:最多可以将两个32位寄存器和一个32位有符号常数相加以计算出一个内存地址。其中一个寄存器可以选择性地乘以2、4或8。
这些寻址模式可与许多x86指令一起使用(我们将在下一节中描述它们)。这里我们举例说明一些使用mov指令在寄存器和内存之间传输数据的情况。该指令有两个操作数:第一个是目标操作数,第二个是源操作数。
一些使用地址计算进行mov指令的示例如下:
mov eax, [ebx] ; 将EBX所包含的地址处4字节大小的数据移动到EAX
mov [var], ebx ; 将EBX内容移动到变量var所对应位置处4字节大小空间。(注意,var是一个32位常量)
mov eax, [esi-4] ; 将ESI + (-4)处4字节大小的数据移动到EAX
mov [esi+eax], cl ; 将CL内容移动到地址ESI+EAX处的一个字节中
mov edx, [esi+4*ebx] ; 将地址ESI+4*EBX处的4字节数据移动到EDX
一些无效的地址计算示例包括:
mov eax, [ebx-ecx] ; 只能添加寄存器值
mov [eax+esi+edi], ebx ; 地址计算中最多只能有2个寄存器
Size指令
通常情况下,可以从汇编代码指令中推断出给定内存地址上数据项的预期大小。例如,在上述所有指令中,可以根据寄存器操作数的大小推断出内存区域的大小。当我们加载一个32位寄存器时,汇编器可以推断我们所引用的内存区域宽度为4字节。当我们将一个字节寄存器的值存储到内存中时,汇编器可以推断我们希望地址引用一字节内存。
然而,在某些情况下,所引用的内存区域的大小是不明确的。考虑指令mov [ebx],2. 这个指令应该将值2移动到EBX地址处的单个字节吗?也许它应该将整数表示为32位整数,并将其移动到以EBX地址开始的4个字节中。由于两者都是有效可能解释,请显式地告知汇编器哪种解释是正确的。BYTE PTR、WORD PTR和DWORD PTR这些大小指示符就起到了这个目标,分别表示1、2和4个字节。
例如:
mov BYTE PTR [ebx], 2 ; 将值2移动到保存在EBX中地址处单个字节。
mov WORD PTR [ebx], 2 ; 将整数表示为16位整数并将其移动到以EBX地址开始处长度为2个字节的区域。
mov DWORD PTR [ebx], 2 ; 将整数表示为32位整数并将其移动到以EBX地址开始处长度为4个字节的区域。
指令
机器指令通常分为三类:数据移动、算术/逻辑和控制流。在本节中,我们将查看每个类别中来自x86指令的重要示例。这一部分不应被视为x86指令的详尽列表,而是一个有用的子集。完整列表请参阅Intel x86 Instruction Set Reference。
我们使用以下符号表示:
<reg32> 任意32位寄存器(EAX、EBX、ECX、EDX、ESI、EDI、ESP或EBP)
<reg16> 任意16位寄存器(AX、BX、CX或DX)
<reg8> 任意8位寄存器(AH,BH,CH,DH,AL,BL,CL或DL)
<reg> 任意寄存器
<mem> 内存地址(例如[eax],[var + 4]或dword ptr [eax+ebx])
<con32> 任意32位常数
<con16> 任意16位常数
<con8> 任意8位常数
<con> 任意8位、16位或32位常数
数据移动指令
mov — Move (Opcodes: 88, 89, 8A, 8B, 8C, 8E, …)
mov 指令将第二个操作数所引用的数据项(即寄存器内容、内存内容或常量值)复制到第一个操作数所引用的位置(即寄存器或内存)。虽然可以进行寄存器之间的移动,但不能直接进行内存之间的移动。在需要进行内存传输的情况下,源内存内容必须首先加载到一个寄存器中,然后才能被保存到目标内存地址。
语法
mov <reg>,<reg>
mov <reg>,<mem>
mov <mem>,<reg>
mov <reg>,<const>
mov <mem>,<const>
示例
mov eax, ebx — 将 ebx 中的值复制到 eax 中
mov byte ptr [var], 5 — 将值 5 存储到 var 所在位置上的字节中
push — Push stack (Opcodes: FF, 89, 8A, 8B, 8C, 8E, …)
push指令将其操作数放置在内存地址[ESP]处32位位置的内容上。具体来说,push首先将ESP减4,然后将其操作数放置在地址[ESP]处的内容中。由于x86堆栈向下增长(即从高地址到低地址增长),所以通过push来递减ESP(堆栈指针)。
语法
push <reg32>
push <mem>
push <con32>
示例
push eax - 将eax推入堆栈
push [var] - 将位于var地址处的4个字节推入堆栈
pop — Pop stack
pop指令将硬件支持的栈顶的4字节数据元素移除,并存入指定操作数(即寄存器或内存位置)。它首先将位于内存位置[SP]处的4字节数据移动到指定的寄存器或内存位置,然后将SP增加4。
语法
pop <reg32>
pop <mem>
示例
pop edi — 将栈顶元素弹出并保存到EDI中。
pop [ebx] — 将栈顶元素弹出并保存到从EBX开始的四个字节所在的内存位置。
lea — Load effective address
lea指令将其第二个操作数指定的地址放入其第一个操作数指定的寄存器中。请注意,只计算并将有效地址放入寄存器中,不加载内存位置的内容。这对于获取内存区域的指针非常有用。
语法
lea <reg32>,<mem>
示例
lea edi, [ebx+4*esi] — 将EBX+4*ESI的值放入EDI中。
lea eax, [var] — 将var变量的值放入EAX中。
lea eax, [val] — 将val变量的值放入EAX中。
算术和逻辑指令
add — Integer Addition
add 指令将其两个操作数相加,并将结果存储在第一个操作数中。请注意,虽然两个操作数都可以是寄存器,但最多只能有一个操作数是内存位置。
语法
add <reg>,<reg>
add <reg>,<mem>
add <mem>,<reg>
add <reg>,<con>
add <mem>,<con>
示例
add eax, 10 — EAX ← EAX + 10
add BYTE PTR [var], 10 — 将值为10的字节添加到存储在内存地址var处的单个字节上
sub — Integer Subtraction
sub 指令将其第二个操作数的值从第一个操作数的值中减去,并将结果存储在第一个操作数中。与 add 相同,
语法
sub <reg>,<reg>
sub <reg>,<mem>
sub <mem>,<reg>
sub <reg>,<con>
sub <mem>,<con>
示例
sub al, ah — AL ← AL - AH
sub eax, 216 — 将EAX中存储的值减去216
inc, dec — Increment, Decrement
inc 指令将操作数的内容增加一。dec 指令将操作数的内容减少一。
语法
inc <reg>
inc <mem>
dec <reg>
dec <mem>
示例
dec eax — 从 EAX 的内容中减去一。
inc DWORD PTR [var] — 将存储在 var 地址处的32位整数增加一。
imul — Integer Multiplication
imul指令有两种基本格式:双操作数(上面的前两个语法列表)和三操作数(上面的最后两个语法列表)。
双操作数形式将其两个操作数相乘,并将结果存储在第一个操作数中。结果(即第一个)操作数必须是寄存器。
三操作数形式将其第二个和第三个操作数相乘,并将结果存储在其第一个操作数中。同样,结果操作数必须是寄存器。此外,第三个操作数组限制为常量值。
语法
imul <reg32>,<reg32>
imul <reg32>,<mem>
imul <reg32>,<reg32>,<con>
imul <reg32>,<mem>,<con>
示例
imul eax, [var] - 将EAX的内容与内存位置var的32位内容相乘。将结果存储在EAX中。
imul esi, edi, 25 - ESI → EDI * 25
idiv — Integer Division
idiv 指令将由将 EDX 视为最高四个字节和 EAX 视为最低四个字节构成的 64 位整数内容,除以指定的操作数值。除法的商结果存储在 EAX 中,而余数则放置在 EDX 中。
语法
idiv <reg32>
idiv <mem>
示例
idiv ebx — 将 EDX:EAX 的内容除以 EBX 的内容。将商放置在 EAX 中,余数放置在 EDX 中。
idiv DWORD PTR [var] — 将 EDX:EAX 的内容除以存储在内存位置 var 处的 32 位值。将商放置在 EAX 中,余数放置在 EDX 中。
and, or, xor — Bitwise logical and, or and exclusive or
这些指令在操作数上执行指定的逻辑运算(分别是逻辑位与、或和异或),将结果放置在第一个操作数位置。
语法
and <reg>,<reg>
and <reg>,<mem>
and <mem>,<reg>
and <reg>,<con>
and <mem>,<con>
or <reg>,<reg>
or <reg>,<mem>
or <mem>,<reg>
or <reg>,<con>
or <mem>,<con>
xor <reg>,<reg>
xor <reg>,<mem>
xor <mem>,<reg>
xor <reg>,<con>
xor <mem>,<con>
示例
and eax, 0fH — 清除 EAX 的除最后4位之外的所有位。
xor edx, edx — 将 EDX 的内容设置为零。
not — Bitwise Logical Not
在操作数内容上进行逻辑取反(即翻转操作数中的所有位值)。
语法
not <reg>
not <mem>
示例
not BYTE PTR [var] — 取反内存位置 var 处字节中的所有位。
neg — Negate
执行操作数内容的二进制补码取反。
语法
neg <reg>
neg <mem>
示例
neg eax — EAX → -EAX
shl, shr — Shift Left, Shift Right
这些指令将第一个操作数的位内容向左和向右移动,并用零填充结果中的空位。被移动的操作数可以最多向上或向下移动31个位置。要进行的位移数量由第二个操作数指定,它可以是8位常量或寄存器CL。在任何情况下,大于31的位移计数会模32执行。
语法
shl <reg>,<con8>
shl <mem>,<con8>
shl <reg>,<cl>
shl <mem>,<cl>
shr <reg>,<con8>
shr <mem>,<con8>
shr <reg>,<cl>
shr <mem>,<cl>
示例
shl eax, 1 — 将EAX值乘以2(如果最高有效位为0)
shr ebx, cl — 在EBX中存储将EBX值除以2n后得到的结果地板值,其中n是CL中的值。
控制流指令
x86处理器维护一个指令指针(IP)寄存器,它是一个32位的值,表示当前指令开始的内存位置。通常情况下,在执行一条指令后,它会递增以指向内存中下一条指令的开始位置。IP寄存器不能直接操作,但可以通过提供的控制流指令隐式地更新。
我们使用符号来引用程序文本中标记过的位置。在x86汇编代码文本中,可以通过输入标签名称后跟冒号来插入标签。例如,
mov esi, [ebp+8]
begin: xor ecx, ecx
mov eax, [esi]
这段代码片段中的第二条指令被标记为begin。在代码其他地方,我们可以使用更方便的符号名称begin来引用该指令所在的内存位置。这个标签只是一种表达位置而不是其32位值的便捷方式。
jmp — Jump
将程序控制流传送到由操作数指示的内存位置处的指令。
语法
jmp <标签>
示例
jmp begin — 跳转到标记为begin的指令。
jcondition — Conditional Jump
这些指令是基于存储在特殊寄存器中的一组条件码的状态进行的条件跳转。机器状态字中包含有关上次执行的算术操作的信息。例如,该字中的一个位表示上次结果是否为零,另一个位表示上次结果是否为负数。根据这些条件码,可以执行多个条件跳转。例如,如果上次算术操作的结果为零,则jz指令将跳转到指定操作数标签处。否则,控制继续按顺序执行下一条指令。
其中一些条件分支具有直观地基于最后执行了特殊比较指令cmp(见下文)而命名的名称。例如,诸如jle和jne之类的条件分支是基于首先对所需操作数执行cmp操作。
语法
je <label>(相等时跳转)
jne <label>(不相等时跳转)
jz <label>(上次结果为零时跳转)
jg <label>(大于时跳转)
jge <label>(大于或等于时跳转)
jl <label>(小于时跳转)
jle <label>(小于或等于时跳转)
示例
cmp eax, ebx
jle done
; 如果EAX寄存器内容小于或等于EBX寄存器内容,则跳到done标签处;否则继续执行下一条指令。
cmp — Compare
比较两个指定操作数的值,适当地设置机器状态字中的条件码。此指令与sub指令等效,只是减法的结果被丢弃而不是替换第一个操作数。
语法
cmp <reg>,<reg>
cmp <reg>,<mem>
cmp <mem>,<reg>
cmp <reg>,<con>
示例
cmp DWORD PTR [var], 10
jeq loop
; 如果存储在变量var位置处的4个字节等于4字节整数常量10,则跳转到标记为loop的位置。
call, ret — Subroutine call and return
这些指令实现了子程序的调用和返回。call 指令首先将当前代码位置推入内存中支持的硬件堆栈(有关详细信息,请参阅 push 指令),然后执行到由标签操作数指示的代码位置的无条件跳转。与简单跳转指令不同,call 指令保存了在子程序完成时返回的位置。
ret 指令实现了一个子程序返回机制。该指令首先从内存中支持的硬件堆栈弹出一个代码位置(有关详细信息,请参阅 pop 指令)。然后它执行到检索到的代码位置的无条件跳转。
语法
call <label>
ret
调用约定
为了让不同的程序员共享代码并开发供多个程序使用的库,并简化子例程的使用,程序员通常采用一种公共的调用约定。调用约定是关于如何调用和返回例程的协议。例如,给定一组调用约定规则,一个程序员无需查看子例程的定义来确定参数应该如何传递给该子例程。此外,给定一组调用约定规则,高级语言编译器可以遵循这些规则,从而允许手写汇编语言例程和高级语言例程相互调用。
实际上有很多可能的调用约定。我们将使用广泛使用的C语言调用约定。遵循这个约定将使您能够编写可安全从C(和C++)代码中进行调用的汇编语言子例程,并且还可以使您能够从汇编语言代码中调用C库函数。
C 调用约定在很大程度上基于硬件支持栈操作指令:push、pop、call 和 ret 指令。子例程参数通过栈传递。寄存器保存在栈上,并且由子例程使用到的局部变量也放置在内存中栈上。大多数处理器上实现的高级过程性语言都采取了类似的调用约定。
调用约定分为两组规则。第一组规则由子例程的调用者使用,第二组规则由子例程的编写者(被调用者)遵守。应强调的是,对这些规则的观察中出现错误会迅速导致严重的程序错误,因为栈将处于不一致状态;因此,在实现自己的子例程中使用调用约定时应格外小心谨慎。
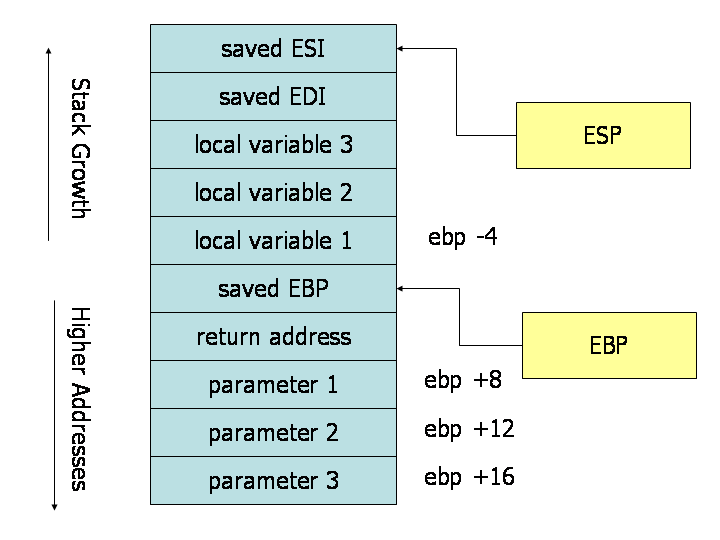
Stack during Subroutine Call
可视化调用约定的操作方式是在子程序执行期间绘制栈附近区域的内容。上图显示了带有三个参数和三个局部变量的子程序执行期间栈中的内容。栈中所示单元格为32位宽度的内存位置,因此单元格之间相隔4字节。第一个参数位于基指针偏移8字节处。在栈上方(基指针下方)的参数之上,调用指令放置了返回地址,因此从基指针到第一个参数还需要额外4字节偏移量。当使用ret指令从子程序返回时,将跳转到存储在栈上的返回地址处。
调用者规则
为了进行子程序调用,调用者应该:
- 在调用子程序之前,调用者应该保存指定的被调用者保存寄存器的内容。被调用者保存寄存器包括EAX、ECX和EDX。由于被调用的子程序可以修改这些寄存器的值,如果在子程序返回后,调用者依赖它们的值,则必须将这些寄存器中的值推入堆栈(以便在子程序返回后恢复)。
- 要将参数传递给子程序,在调用之前将它们推入堆栈。参数应按照倒序推送(即最后一个参数先)。由于堆栈向下增长,第一个参数将存储在最低地址处(历史上使用此反转参数来允许函数接收可变数量的参数)。
- 要调用子程序,请使用call指令。此指令会将返回地址放置在堆栈上方,并跳转到子程序代码。这样就会触发执行该子程序,其遵循以下被呼叫者规则。
在子程序返回后(紧跟着调用指令),调用者可以期望在寄存器EAX中找到子程序的返回值。为了恢复机器状态,调用者应该:
- 从堆栈中移除参数。这将使堆栈恢复到调用之前的状态。
- 通过弹出它们来恢复保存在调用者保存寄存器(EAX、ECX、EDX)中的内容。调用者可以假设其他寄存器没有被子程序修改。
示例
下面的代码显示了一个遵循调用者规则的函数调用。调用者正在调用一个名为_myFunc的函数,该函数接受三个整数参数。第一个参数在EAX中,第二个参数是常量216;第三个参数位于内存位置var。
push [var] ; 先推送最后一个参数
push 216 ; 推送第二个参数
push eax ; 最后推送第一个参数
call _myFunc ; 调用函数(假设使用C命名)
add esp, 12
请注意,在调用返回之后,调用者使用add指令清理堆栈。我们在堆栈上有12字节(3个参数 * 每个4字节),而且堆栈向下增长。因此,要摆脱这些参数,我们只需将12加到堆栈指针上。
_myFunc产生的结果现在可以在寄存器EAX中使用。调用者保存寄存器(ECX和EDX)的值可能已经改变。如果在调用之后需要继续使用它们,则需要在调用之前将它们保存到堆栈上,并在之后恢复它们。
被调用者规则
子程序的定义应遵循以下规则:
- 在子程序开始时,将EBP的值推入堆栈,然后使用以下指令将ESP的值复制到EBP中:
push ebp
mov ebp, esp
- 这个初始操作维护了基指针EBP。按照惯例,基指针用作在堆栈上查找参数和局部变量的参考点。当一个子程序正在执行时,基指针保存了从子程序开始执行时的堆栈指针值的副本。参数和局部变量始终位于已知、常量偏移量处于基指针值之外。我们在子程序开始时推送旧的基指针值,以便在子程序返回时可以恢复适当的调用者基指针值。请记住,调用者不希望子程序改变基指针的值。然后我们将堆栈指针移动到EBP中,以获得访问参数和局部变量所需的参考点。
接下来,在堆栈上为局部变量分配空间。回忆一下,堆栈向下增长,因此要在堆栈顶部留出空间,则需要减小堆栈指钉器(stack pointer)。减小堆校标志器(stack pointer) 的数量取决于所需本地变量数目及其大小 。例如,如果需要3个本地整数(每个4字节),则堆栈指针需要减小12以为这些局部变量腾出空间(即sub esp, 12)。与参数一样,局部变量将位于基指针的已知偏移处。 - 接下来,保存函数使用的被调用者保存寄存器的值。要保存寄存器,请将它们推入堆栈。被调用者保存的寄存器是EBX、EDI和ESI(ESP和EBP也会按照调用约定保留,但在此步骤中不需要推入堆栈)。
完成这三个操作后,子程序体可以继续执行。当子程序返回时,必须按照以下步骤进行:
- 将返回值放在EAX中。
- 恢复任何已修改的被调用者保存寄存器(EDI和ESI)的旧值。通过从堆栈弹出它们来恢复寄存器内容。应该按照相反顺序弹出这些寄存器,即与推送它们时相反顺序。
释放局部变量。处理这种情况可能显而易见的方法是向堆校标志器添加适当的值(因为空间是通过从堆校标志器减去所需数量来分配)。实际上,在释放变量时一个更少容易出错 的方法是将基指针中的值移动到堆校标志器:mov esp, ebp。这样做是因为基指针始终包含在分配局部变量之前堆校标志器所包含的值。 - 在返回之前,通过从堆栈弹出EBP来恢复调用者的基指针值。回想一下,在进入子程序时我们首先做的事情就是推送基指针以保存其旧值。
- 最后,通过执行ret指令返回给调用者。该指令将找到并从堆校中删除适当的返回地址。
请注意,被调用者的规则可以清晰地分为两半,基本上是彼此镜像。规则的前半部分适用于函数的开头,并且通常被称为函数的序言。规则的后半部分适用于函数的结尾,并且因此通常被称为函数的尾声。
示例
这是一个遵循被调用者规则的示例函数定义:
.486
.MODEL FLAT
.CODE
PUBLIC _myFunc
_myFunc PROC
; 子程序序言
push ebp ;保存旧的基指针值。
mov ebp, esp ; 设置新的基指针值。
sub esp, 4 ; 留出一个4字节的局部变量空间。
push edi ; 保存函数将修改的寄存器的值,
push esi ; 该函数使用EDI和ESI寄存器。
; (不需要保存EBX,EBP或ESP)
; 子程序主体
mov eax, [ebp+8] ; 将参数1的值移动到EAX中。
mov esi, [ebp+12] ; 将参数2的值移动到ESI中。
mov edi, [ebp+16] ; 将参数3的值移动到EDI中。
mov [ebp-4], edi ; 将EDI移动到局部变量中。
add [ebp-4], esi ; 将ESI加入局部变量中。
add eax, [ebp-4] ; 将局部变量内容加入EAX(最终结果)
; 子程序尾声
pop esi ; 恢复寄存器值
pop edi
mov esp, ebp ; 回收本地变量空间
pop ebp ; 恢复调用者的基指针值
ret
_myFunc ENDP
END
子程序序言执行保存堆栈指针在EBP(基指针)的快照,通过减少堆栈指针来分配局部变量,并将寄存器值保存在堆栈上的标准操作。
在子程序体中,我们可以看到基指针的使用。参数和局部变量都位于相对于基指针的恒定偏移处,在子程序执行期间保持不变。特别地,我们注意到由于参数是在调用子程序之前放置到堆栈上的,它们总是位于基指针下方(即较高地址)的位置。子程序的第一个参数始终可以在内存位置EBP + 8找到,第二个参数为EBP + 12,第三个为EBP + 16。同样地,由于局部变量是在设置了基指针后分配的,它们总是位于基指针上方(即较低地址)的位置。特别地,第一个局部变量始终位于EBP - 4处,第二个为EBP - 8等等。这种常规使用基指针使我们能够快速识别函数体内部使用的局部变量和参数。
函数尾声实际上是函数序言的镜像反映。调用者寄存器值从堆栈中恢复出来,并通过重置堆栈指针来释放局部变量;调用者的基指针值被恢复,然后使用ret指令返回到调用者中适当的代码位置。