ptmalloc2源码分析
1. malloc函数入口
直接在glibc中查找malloc函数的话是找不到的 ,因为malloc只是一个alias,真正的实现函数名是__libc_malloc :
// malloc/malloc.c
strong_alias (__libc_malloc, malloc)
// include/libc-symbols.h
#define strong_alias(a, b) _strong_alias(a, b)
#define _strong_alias(a, b) \
extern __typeof(a) b __attribute__ ((alias (#a)));
2. malloc_chunk数据结构
malloc中用到的chunk数据结构名称是malloc_chunk,这个数据结构是malloc管理堆的基本数据结构,具体定义是:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
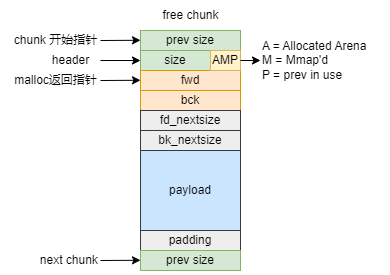
2.1 free chunk
把上面的malloc_chunk数据结构直接图形化,结果就是free chunk的示意图,allocated chunk的示意图后面再讲,这里先展示free chunk:
free chunk
注意上面图中的chunk_size和malloc返回地址都要能被8整除。
同时mchunk_prev_size这个区域类似于隐式空闲链表和显式空闲链表中的footer,只是malloc代码把footer部分放到了size之前。由于chunk_size和malloc的返回指针mem都要能被8整除,把footer放到header之前并变为mchunk_prev_size字段,这样在mem指针之前就有了8个字节的数据,这样在mem指针之前就有了8个字节的数据,这样只要当前chunk的开始指针8字节对齐,那么mem指针自然也就8字节对齐,这样处理起来会简单一些。
图中标注出了mchunk_size区域的AMP三个flag的含义,A表示这个chunk是否属于main arena;M表示这个chunk是否是由mmap分配而来;P表示当前chunk的前一个chunk是否是allocated chunk。再来看fd和bk两个field,它们分别指向forward和backward方向的第一个free chunk。而fd_nextsize和bk_nextsize这两个指针只会在large chunk中用得到。
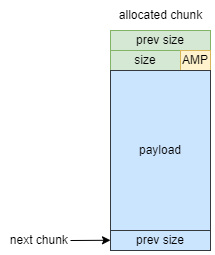
2.2 allocated chunk
在chunk状态是allocated的时候,原本free chunk中的fd、bk、fd_nextsize、bk_nextsize这些字段全部变成用来存放payload(有效数据)
还有mchunk_prev_size这个字段也要注意一下,它有两种解释:
- 在previous chunk是free chunk的时候:这个字段的值是前一个chunk的size
- 在previous chunk是allocated chunk的时候:这个字段里的值可能是前一个chunk的payload
根据前面的这些说明,allocated chunk结构如下图所示:
allocated chunk
需要注意的是,当一个chunk的P标志位为1时,说明这个chunk正在被使用中,因此next chunk的prev_size字段就可以merge到current chunk的payload区域中。
3. heap_info和malloc_state
它们是堆管理的核心全局数据结构,下面是它们的定义:
// malloc/arena.c
typedef struct _heap_info
{
mstate ar_ptr; /* Arena for this heap. */
struct _heap_info *prev; /* Previous heap. */
size_t size; /* Current size in bytes. */
size_t mprotect_size; /* Size in bytes that has been mprotected
PROT_READ|PROT_WRITE. */
/* Make sure the following data is properly aligned, particularly
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
MALLOC_ALIGNMENT. */
char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK];
} heap_info;
malloc_state表示一个arena的header细节。主线程的arena是一个全局变量,不是heap segment的一部分。其他线程的arena header(malloc_state 结构)本身存储在heap segment中。Non main arenas可以有与之关联的多个heap(这里“heap”指代内部结构,而不是heap segment)。
// malloc/malloc.c
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
4. bin
在malloc的实现中,一个管理空闲chunk的链表被称为一个bin,下面介绍一下malloc的实现中的几种bin。
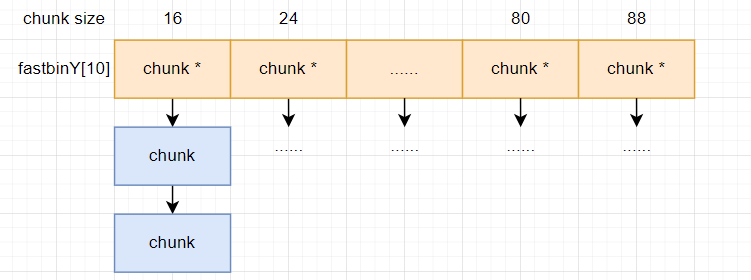
4.1 fast bin
fast bin 在malloc_state中定义如下,NFASTBINS = 10,所以fast bin的个数为10个:
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
这是分配速度最快的一种bin,10个bin对应的chunk大小如下:
fast bin
malloc中的fast bin有下面几个特性:
- fast bin用的是单链表而不是双链表,即只用了malloc_chunk中的fd这个指针,插入和删除chunk都是在表头进行
- fast bin的P标志位都是1,通常情况下不对free chunk进行merge
- fast bin的chunk size是按照8字节递增的,如上面图1所示
操作fast bin的两个重要的宏定义代码如下:
#define fastbin_index(sz) (((sz) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
4.2 small bin
small bin 是用来管理小于512字节的chunk的,一共有62个,它在malloc_state中的定义如下:
mchunkptr bins[NBINS * 2 - 2];
这个bins array中有三种bin,其中small bin就在其中:
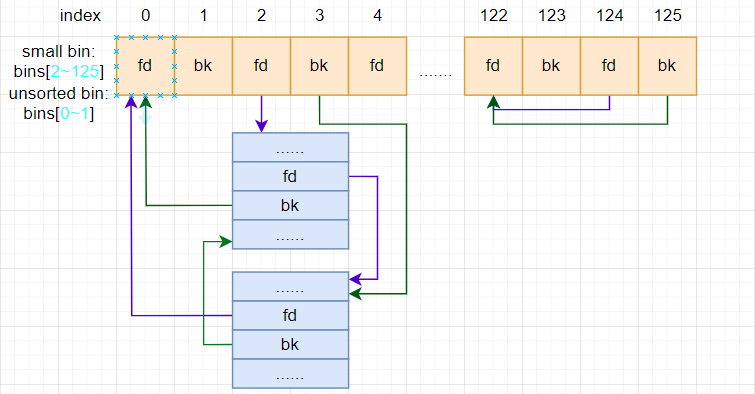
small bins
从这个图中可以看到,每个small bin使用了bins array中的两个元素,以0、1、2、3四个元素为例,代码中把这部分空间强制转换成了malloc_chunk类型,这样根据malloc_chunk数据结构的定义,3、4两个元素就对应了malloc_chunk中的fd、bk指针,它们作为第一个small bin的表头,分别用来指向forward和backward方向的malloc_chunk。
有62个small bins。 Small bins比large bins快,但比fast bin慢。 每个bin维护一个双向链表。 插入发生在“HEAD”,而删除发生在“TAIL”(以FIFO方式)。与fast bin一样,每个bin都具有相同大小的chunk。 这62个bins所管理的chunk size分别为:16、24、…、504字节。释放时,small chunks可能会被合并在一起,然后最终进入unsorted bin中。
4.3 large bin
large bin用来管理大于等于512字节的chunk,和small bin一样,使用malloc_state中的bins array来存放链表头,在bins array中的所处位置如下:

large bins
large bin一共有63个,和small bin一样也是通过双链表来管理chunk,和small bin不同的是,每个large bin中的chunk size可以不同,处在一个规定好的区间内,具体如下表:
| idx | category | step | bin size range |
|---|---|---|---|
| 1 | unsorted | N/A | N/A |
| [2,63] | small | 1«3 | [16, 504] |
| [64,94] | large | 1«6 | [512, 512+30*step] |
| [95,111] | large | 1«9 | [2496, 2496+16*step] |
| [112,120] | large | 1«12 | [11200, 11200+8*step] |
| [121,123] | large | 1«15 | [48064, 48064+2*step] |
| [124,125] | large | 1«18 | [146368, 146368+step] |
| 126 | large | N/A | [670656, -] |
因为large bin的每个bin中的chunk size有所不同,所以分配时会检查每个free chunk,选择匹配请求大小的最小free chunk,这种搜索算法的缺点是平均检索时间较长。同时,就像small chunks一样,当释放时,large chunks可能会在最终进入unsorted bin之前合并在一起。
4.4 unsorted bin
unsorted bin相当于small bin和large bin的一个缓存,可以让malloc有第二次机会重新利用最近free的chunk,它只有一个bin,同样使用malloc_state中的bins array来存放表头,它在bins array中的位置如下图:
small bins
5. 特殊chunk
5.1 top chunk
top chunk是堆最上面的一段空间,它不属于任何bin,当所有的bin都无法满足分配要求时,就要从这块区域里来分配,分配的空间返给用户,剩余部分形成新的top chunk,如果top chunk的空间也不满足用户的请求,就要使用brk或者mmap来向系统申请更多的堆空间(main arena使用brk、sbrk,thread arena使用mmap),对于top chunk,始终设置PREV_INUSE标志。代码中也有一段对top chunk的注释:
The top-most available chunk (i.e., the one bordering the end of available memory) is treated specially. It is never included in any bin, is used only if no other chunk isavailable, and is released back to the system if it is very large (see M_TRIM_THRESHOLD).
在free chunk的时候,如果chunk size不属于fastbin的范围,就要考虑是不是和top chunk挨着,如果挨着,就要merge到top chunk中。
5.2 last remainder chunk
这个chunk在malloc_state中的定义如下:
// The remainder from the most recent split of a small request
mchunkptr last_remainder;
这个特殊chunk是被维护在unsorted bin中的,代码中有两个地方改变了它的值:
- 如果用户申请的size属于small bin的,但是又不能精确匹配的情况下,这时候和large bin里的分配策略一样采用最佳匹配(比如申请128字节,但是对应的bin是空,只有256字节的bin非空,这时候就要从256字节的bin上分配),这样会split chunk成两部分,一部分返给用户,另一部分形成last remainder chunk,插入到unsorted bin中。
- 在使用fast bin和small bin分配失败后,会尝试从unsorted bin中分配,这时候如果同时满足下面几个条件,那么就将the only free chunk进行split,一部分返回用户,剩余的部分作为新的 last remainder chunk,插入到 unsorted bin的链表头:
- 申请的size在small bin的范围内
- unsorted bin仅有一个free chunk
- the only free chunk是last_remainder
- the only free chunk size满足进行split
6. malloc入口函数:__libc_malloc
介绍完malloc的关键数据结构之后继续来看malloc入口函数__libc_malloc,下面是这个函数的关键代码:
void* __libc_malloc (size_t bytes) {
mstate ar_ptr;
void *victim;
// First part: callback
void *(*hook) (size_t, const void *)
= atomic_forced_read (__malloc_hook);
if (__builtin_expect (hook != NULL, 0))
return (*hook)(bytes, RETURN_ADDRESS (0));
// Second part
arena_get (ar_ptr, bytes);
// Third part
victim = _int_malloc (ar_ptr, bytes);
return victim;
}
从上面代码可以看出,主要包含callback、arena_get、_int_malloc这几步,我们把callback和arena_get当作初始化的过程,_int_malloc作为实际分配的过程。
6.1 step1: callback
先看first part,如下面两句,第一句是给函数指针变量赋值,第二句是函数调用:
void *(*hook) (size_t, const void *)
= atomic_forced_read (__malloc_hook);
if (__builtin_expect (hook != NULL, 0))
return (*hook)(bytes, RETURN_ADDRESS (0));
hook是一个函数指针变量,被赋值成了__malloc_hook,后者定义如下:
void *weak_variable (*__malloc_hook)
(size_t __size, const void *) = malloc_hook_ini;
__malloc_hook被初始化成了malloc_hook_ini,后者定义如下:
void* malloc_hook_ini (size_t sz, const void *caller) {
__malloc_hook = NULL;
ptmalloc_init ();
return __libc_malloc (sz);
}
这里malloc_hook又被赋值成了NULL,然后再重新调用libc_malloc,这样就可以保证在多次调用__libc_malloc的情况下,这个函数中的中的hook回调函数只会被调用一次。
这个函数里的ptmalloc_init的关键代码如下:
void ptmalloc_init (void) {
if (__malloc_initialized >= 0)
return;
__malloc_initialized = 0;
thread_arena = &main_arena;
malloc_init_state (&main_arena);
__malloc_initialized = 1;
}
通过__malloc_initialized这个全局flag来检测是不是已经初始化过了,如果没有,则把main_arena设成当前的thread_arena,这是因为初始化肯定是主线程在做,而主线程用的是main_arena,然后再调用malloc_init_state进一步初始化,malloc_init_state定义如下:
void malloc_init_state (mstate av) {
int i;
mbinptr bin;
// part1
for (i = 1; i < NBINS; ++i) {
bin = bin_at (av, i);
bin->fd = bin->bk = bin;
}
// part2
if (av == &main_arena)
set_max_fast(DEFAULT_MXFAST);
av->top = initial_top (av);
}
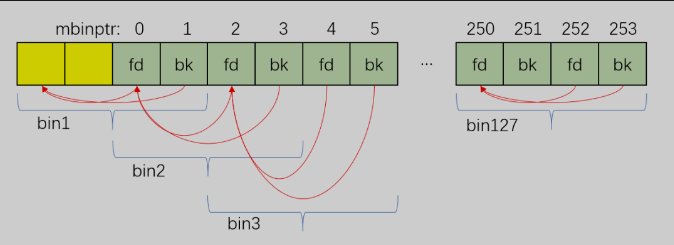
part1部分使用bin_at这个宏对malloc_state中的bins数组进行初始化,如下所示:
#define bin_at(m, i) \
(mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \
- offsetof (struct malloc_chunk, fd))
在经过part1的初始化之后,malloc_state中的bins array初始化成了下图所示:
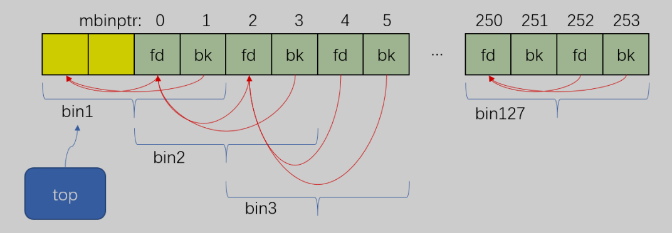
part2把malloc_state中的top初始化成了指向bin1,修改top后如下图所示:
6.2 step2: arena_get
这是一个宏,源代码中对这个宏有一段注释:
arena_get acquires an arena and locks the corresponding mutex.
First, try the one last locked successfully by this thread.
(This is the common case and handled with a macro for speed.)
Then, loop once over the circularly linked list of arenas.
If no arena is readily available, create a new one.
In this latter case, `size’ is just a hint as to how much
memory will be required immediately in the new arena.
arena_get的代码如下:
#define arena_get(ptr, size) do { \
ptr = thread_arena; \
if (ptr) { __libc_lock_lock (ptr->mutex); } \
else { ptr = arena_get2 ((size), NULL); } \
} while (0)
主要的实现在arena_get2这个函数里,它的主要作用是为当前线程获取一个可用的arena,这个函数的实现很复杂,考虑了各种情况,函数里又嵌套调用了多个函数,关键的流程如下图所示:
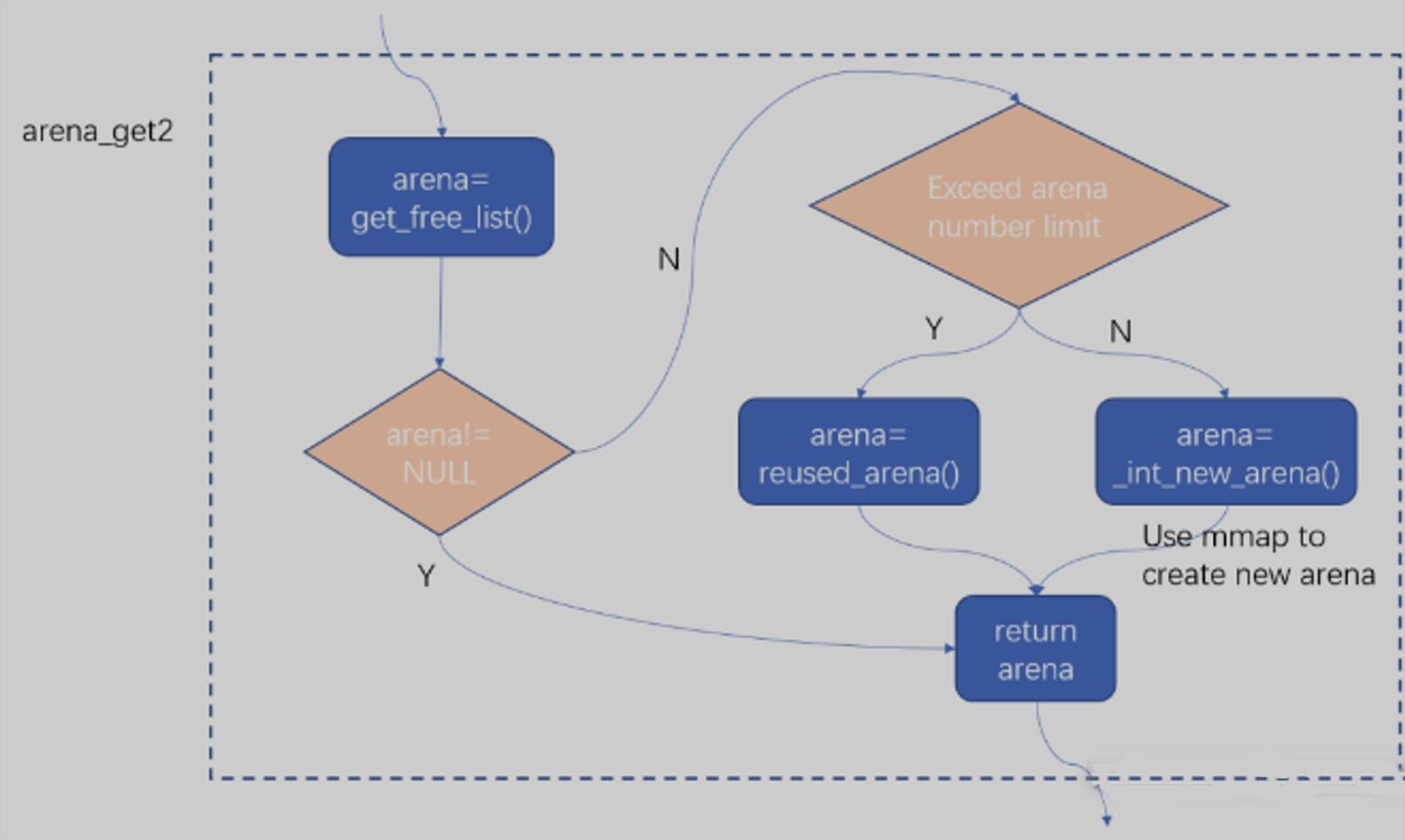
可以看到,arena_get2的flow里主要调用了get_free_list、reused_arena、_int_new_arena这三个函数,它们的作用从函数名就可以看出来,这三个函数里面_int_new_arena更重要一些,后面着重讲一下这一个函数。
6.2.1 _int_new_arena
这个函数是用来在arena的个数超出限制之前创建新的arena的,关键代码如下:
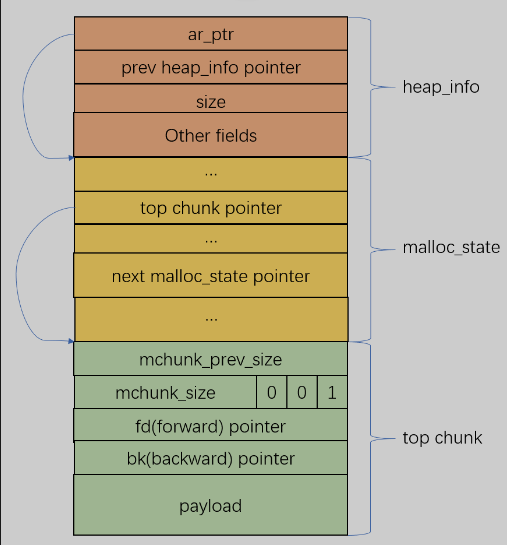
static mstate _int_new_arena(size_t size) {
// 用指定size创建一个新的heap_info对象
heap_info *h = new_heap(size + (sizeof(heap_info)
+ sizeof(malloc_state) + MALLOC_ALIGNMENT), mp_.top_pad);
if (!h) {
// 如果size过大导致new_heap失败,则创建一个只包含
// 基础数据结构heap_info和malloc_state的对象
h = new_heap (sizeof (heap_info) + sizeof (malloc_state)
+ MALLOC_ALIGNMENT, mp_.top_pad);
if (!h) return 0;
}
// 初始化malloc_state
malloc_state *a = h->ar_ptr = (malloc_state *) (h + 1);
malloc_init_state (a);
a->attached_threads = 1;
a->system_mem = a->max_system_mem = h->size;
// 设置malloc_state中的top chunk指针
// 设置top chunk的header
char *ptr = (char *)(a + 1);
top(a) = (mchunkptr)ptr;
set_head(top(a), (((char *)h + h->size) - ptr) | PREV_INUSE);
// 更新malloc_state中的next链表,把新建的arena加到链表中
thread_arena = a;
a->next = main_arena.next;
main_arena.next = a;
return a;
}
下面再用一张memory layout的图示来展示刚创建过的arena:
前面的_int_new_arena函数中调用了new_heap这个函数,这个函数主要是通过mmap对应的系统调用来通过操作系统分配空间,精简过的代码如下:
static heap_info *new_heap(size_t size, size_t top_pad) {
// 通过系统调用分配内存
char *p2 = (char *)MMAP(aligned_heap_area,
HEAP_MAX_SIZE, PROT_NONE, MAP_NORESERVE);
if (__mprotect(p2, size,
mtag_mmap_flags | PROT_READ | PROT_WRITE) != 0) {
__munmap (p2, HEAP_MAX_SIZE);
return 0;
}
// 初始化heap_info结构体
heap_info *h = (heap_info *)p2;
h->size = size;
h->mprotect_size = size;
return h;
}
6.3 step3: _int_malloc
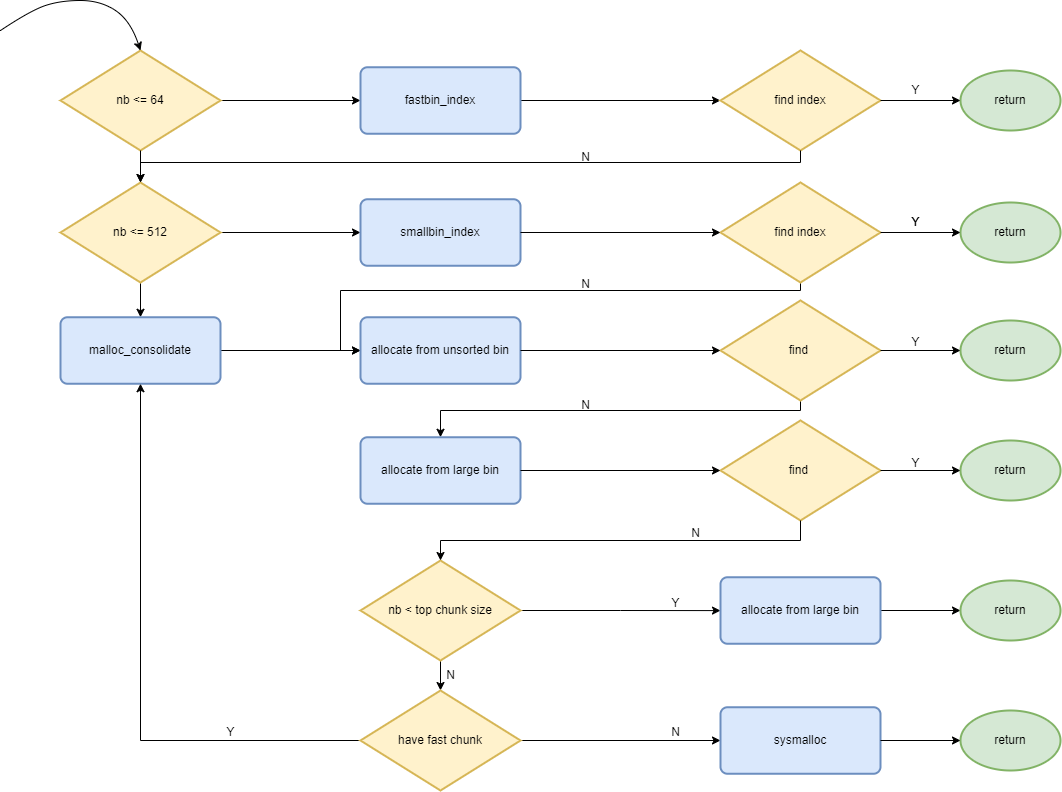
在初始化完bins array,以及通过arena_get2函数确定好使用的arena之后,最后一步就是malloc的具体分配过程了,这个过程就是由_int_malloc这个函数完成的。下面是这个函数的流程图:
在malloc的实现中,需要频繁的插入和删除各个bin中的chunk,很多地方用到了CAS操作,所以介绍一下CAS,比较并交换(compare and swap, CAS),是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。 该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
一个CAS操作等价于以下c代码的原子实现:
int cas(long *addr, long old, long new)
{
/* Executes atomically. */
if(*addr != old)
return 0;
*addr = new;
return 1;
}
在使用上,通常会记录下某块内存中的_旧值_,通过对_旧值_进行一系列的操作后得到_新值_,然后通过CAS操作将_新值_与_旧值_进行交换。如果这块内存的值在这期间内没被修改过,则_旧值_会与内存中的数据相同,这时CAS操作将会成功执行 使内存中的数据变为_新值_。如果内存中的值在这期间内被修改过,则一般来说_旧值_会与内存中的数据不同,这时CAS操作将会失败,_新值_将不会被写入内存。
6.3.1 从fast bin分配
在_int_malloc的开始,先看申请的内存大小nb是否符合fast bin的限制,符合的话,首先进入fast bin的分配代码:
if (nb <= get_max_fast()) {
idx = fastbin_index(nb);
mfastbinptr *fb = &fastbin(av, idx);
mchunkptr pp;
if ((victim = *fb) != NULL) {
REMOVE_FB(fb, pp, victim); // CAS
void *p = chunk2mem(victim);
/**
* void alloc_perturb (char *p, size_t n);
* If perturb_byte (tunable parameter for malloc using M_PERTURB)
* is non-zero (by default it is 0), sets the n bytes pointed to by p
* to be equal to perturb_byte ^ 0xff.
*/
alloc_perturb(p, bytes);
return p;
}
}
这里会根据nb得到fast bin的index,再根据index,得到指向所在bin的head指针fb,如果这个bin非空,则取第一个chunk,使用REMOVE_FB这个原子操作将其从所在bin删除,并将取到的chunk返回。
6.3.2 从small bin分配
不符合fast bin分配条件的话,会继续看是否符合small bin的分配条件,这部分的代码如下:
if (in_smallbin_range(nb)) {
idx = smallbin_index(nb);
bin = bin_at(av, idx);
if ((victim = last(bin)) != bin) {
bck = victim->bk;
set_inuse_bit_at_offset(victim, nb);
bin->bk = bck;
bck->fd = bin;
if (av != &main_arena)
set_non_main_arena(victim);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
alloc_perturb(p, bytes);
return p;
}
}
这里的处理过程和fast bin类似,也是根据nb定位到所在的bin,所在bin非空的话,就分配成功,返回得到的chunk,并且从所在bin中删除,和fast bin的最大不同之处在于这里操作的是双向链表
6.3.3 合并fast bin到unsorted bin中
在fast bin和small bin都分配失败之后,会把fast bin中的chunk进行一次整理合并,然后将合并后的chunk放入unsorted bin中,这是通过malloc_consolidate这个函数完成的,由于太长了,这里只写一下伪代码,下面也是一样:
function malloc_consolidate(av)
atomic_store_relaxed(av->have_fastchunks, false)
unsorted_bin = unsorted_chunks(av)
maxfb = fastbin(av, NFASTBINS - 1)
fb = fastbin(av, 0)
loop until fb is not greater than maxfb
p = atomic_exchange_acq(fb, NULL)
if p is not equal to 0
loop until p is not equal to 0
// Internal logic
If the previous chunk of the current chunk is free, merge
If the next chunk of the current chunk is free, merge
If the merged chunk is not adjacent to the top chunk
Insert the merged chunk into the unsorted bin
If the merged chunk is adjacent to the top chunk
Reset the starting position of the top chunk
6.3.4 从unsorted bin中分配
在合并fast bin到unsorted bin中后,尝试从unsorted bin中分配:
loop forever
iters = 0
while (victim = unsorted_chunks(av)->bk) is not equal to unsorted_chunks(av)
bck = victim->bk
size = chunksize(victim)
next = chunk_at_offset(victim, size)
if in_smallbin_range(nb) and bck equals unsorted_chunks(av) and victim equals av->last_remainder and size is greater than (nb + MINSIZE)
// Do something
return p
if size equals nb
// Do something
return p
if in_smallbin_range(size)
// Do something for small bin
else
// Do something for large bin
// Remove the current chunk from the unsorted bin
// Do something
if iters incremented by 1 is greater than or equal to 10000
break
6.3.5 从large bin中分配
在从unsorted bin分配失败之后,准备从large bin分配:
loop forever
if not in_smallbin_range(nb)
bin = bin_at(av, idx)
victim = first(bin)
if victim is not equal to bin and chunksize_nomask(victim) is greater than or equal to nb
// 1. Use best fit algorithm to find the most suitable chunk size
// 2. Split this chunk, return a part to the user,
// assign the remaining part to the remainder in malloc_state,
// and insert it into the unsorted bin
return p
increment idx by 1
bin = bin_at(av, idx)
block = idx2block(idx)
map = av->binmap[block]
bit = idx2bit(idx)
loop forever
// If a suitable bin is not found, jump to use_top to allocate using the top chunk
// If a suitable bin is found:
// 1. Use best fit algorithm to find the most suitable chunk size
// 2. Split this chunk, return a part to the user,
// assign the remaining part to the remainder in malloc_state,
// and insert it into the unsorted bin
6.3.6 从top chunk中分配
从large bin分配失败之后,准备从top chunk分配,如果还是不行,那就要执行系统调用申请新内存了。
loop forever
victim = av->top
size = chunksize(victim)
if size is greater than or equal to (nb + MINSIZE)
// If the size of the top chunk meets the requirement, allocation is successful
// The remaining part becomes the new top chunk and also the remainder
remainder_size = size - nb
remainder = chunk_at_offset(victim, nb)
av->top = remainder
set_head(victim, ...)
set_head(remainder, remainder_size OR PREV_INUSE)
p = chunk2mem(victim)
return p
else if av->have_fastchunks is true
// If the fast bin flag is set,
// Release the contents of the fast bin back to the unsorted bin
// and reacquire the index of the bin where the request size is located
malloc_consolidate(av)
if in_smallbin_range(nb)
idx = smallbin_index(nb)
else
idx = largebin_index(nb)
else
// If the top chunk also does not meet the request size,
// use a system call to increase the top chunk or allocate a new heap
p = sysmalloc(nb, av)
return p
increment idx by 1
bin = bin_at(av, idx)
block = idx2block(idx)
map = av->binmap[block]
bit = idx2bit(idx)
loop forever
// If a suitable bin is not found, jump to use_top to allocate using the top chunk
// If a suitable bin is found:
// 1. Use best fit algorithm to find the most suitable chunk size
// 2. Split this chunk, return a part to the user,
// assign the remaining part to the remainder in malloc_state,
// and insert it into the unsorted bin
6.4 _int_malloc 总结
如果申请的 chunk 的大小位于 fastbin 范围内,从 fastbin 的头结点开始取 chunk。在fastbin中没找到,如果获取的内存块的范围处于 small bin 的范围,那么尝试从small bin中申请chunk。当 fast bin、small bin 中的 chunk 都不能满足用户请求 chunk 大小时,就会考虑是不是 large bin。先将fast bin 中有可能能够合并的 chunk 先进行合并后放到 unsorted bin 中,不能够合并的就直接放到 unsorted bin 中,然后再在下面的大循环中进行相应的处理。在这个大循环中会在分配 large chunk 之前对堆中碎片 chunk 进行合并,以便减少堆中的碎片。
接下来进入一个无限循环 for_loop,for_loop中还有一个至多循环1万次的while_loop,在while_loop中会按照 FIFO 的方式逐个将 unsorted bin 中的 chunk 取出来;如果是 small request,则优先考虑last_reminder_chunk是否满足条件,是的话,直接返回,然后再考虑迭代到的chunk_size是不是恰好满足条件,是的话,直接返回;如果不是 small request,就会尝试从 large bin 中分配用户所需的内存。在遍历链表的过程中,会将 chunk 放到对应的 bin 中,直到找到符合用户请求条件的chunk。在while_loop结束后,说明在unsorted bin中没有找到合适的chunk。就会看请求的 chunk 是否在 large chunk 范围内,如果是,就在对应的 bin 中从小到大进行扫描,找到第一个合适的。
如果还是不行,那就要查找比当前bin更大的fast/small/large bin。在这个查找过程中会通过binmap来加快检索速度。
如果所有的bin中的chunk都没有办法满足要求,那么就只能使用top chunk了,这里会查看分割后的top chunk是否任然满足chunk的最小大小,如果满足那就可以分割后返回。如果不满足,那么判断一下当前 arena 中是否还有 fast chunk。如果有,那么会将fast bin中的chunk合并,然后迁移到unsorted bin中,然后尝试下一次for_loop是否可以分配成功。如果没有,那么就只能通过sysmalloc从系统中申请一点内存了。